начато: 25.07.2010
последнее изменение: 01.09.2013
http://handmade-linux-firewall.narod.ru
http://hlf.netii.net
Содержание
ВступлениеЧасть 1. Концепции
Что мы хотим
Схема сети
Почему рассматривается именно этот вариант схемы?
Проблемы
Основные концепции: потоки, линки, цепочки
Листинг правил iptables для рассматриваемой схемы сети
Конфигурация интерфейсов шлюза
Фильтрация
Сетевые сервисы или чего не должно быть на шлюзе/firewall'е
Контроль доступа
Цепочки фильтрации
Локальная сеть <-> шлюз
Интернет <-> шлюз
Локальная сеть <-> Интернет
Интернет <-> DMZ
Локальная сеть <-> DMZ
Фильтрация и отслеживание соединений (connection tracking)
Маршрутизация (routing)
Один провайдер
Два провайдера
Policy routing
fwmark: NETFILTER+routing
Этапы прохождения пакета через NETFILTER
Входящий трафик через двух провайдеров
Резервирование и переключение: динамическая маршрутизация?
Доступ из внутренних сетей к сети Интернет через один публичный адрес (NAT - трансляция адресов)
Управление трафиком (traffic control: shaping, policing и т.д.)
Управление исходящим трафиком: shaping, scheduling
Входящий трафик и почему им невозможно управлять. Policing
Управление трафиком в рассматриваемом примере
Объединённое управление трафиком на нескольких интерфейсах (IFB, IMQ - одна дисциплина на несколько интерфейсов)
Управление трафиком в downstream-канале
Обьединение трафика на виртуальном IFB-интерфейсе
Настройка дисциплины IFB-интерфейса и создание иерархии классов
Иерархия классов для двух каналов/провайдеров
Классификация трафика при помощи NETFILTER
Управление трафиком и SQUID
Вариант №1: использовать возможности SQUID (версии 2.x) по управлению трафиком
Вариант №2: косвенное влияние на использование канала SQUID'ом плюс частичная "интеграция" с traffic control
Учет (подсчет) трафика (traffic accounting)
Подсчет трафика с помощью conntrackd
Подсчет трафика с помощью ulogd
Учет трафика и SQUID
Roadwarriors: мобильные клиенты. Доступ к внутренним сетям и VPN.
Функционирование VPN с точки зрения фаервола
VPN и маршрутизация
Выбор VPN
Использование ipset. Оптимизация набора правил
iptables-restore: атомарная загрузка набора правил
nftables: преемник iptables и будущее Linux firewall
Часть 2. Реализация
Чем не устроил Shorewall
Предыдущие варианты реализации или "как не надо делать"
Исходные тексты фаервола
Почему perl, а не bash, python и т.д.?
Почему конфигурация не хранится в СУБД или LDAP
Устройство фаервола
Структура каталогов
Поддержка нескольких конфигураций
Общие модули
Конфигурационные файлы
Файл описания шлюза и сетей
Синтаксис файла
Файл описания правил для хостов и сетей
Синтаксис файла
Конфигурация main
Процесс загрузки конфигурация main
Подробнее о функциях firewall.pm
Вопросы без ответов
TODO
Вступление
В данном тексте показан один из возможных вариантов построения интернет-шлюза (небольшой организации) на базе GNU/Linux с функциями фаервола, маршрутизатора. В качестве дистрибутива используется Debian GNU/Linux.
Представлена целостная картина, основанная на реально эксплуатируемой системе.
Изложен один из возможных принципов организации правил NETFILTER, позволяющие относительно легко:
- разработать набор правил
- осуществлять визуальный анализ их логики (по выводу iptables -nvL)
- вносить изменения в конфигурацию фаервола
- автоматизировать фаервол.
Также рассмотрены: маршрутизация (напр. работа через двух провайдеров), управление трафиком, учет трафика, разъяснены некоторые неочевидные моменты, с которыми пришлось столкнуться на практике.
Текст ориентирован на тех, кто хочет увидеть пример реально эксплуатирумого набора
правил iptabels/tc (плох он или хорош - это другой вопрос), разобраться в работе и использовании
подсистем фаервола и управления трафиком в Linux с целью самостоятельного конфигурирования.
Подразумевается, что вы представляете, как продвинутый пользователь/администратор,
что такое iptables, знаете синтаксис команд iptables, в общих чертах возможности NETFILTER
(подсистема ядра для перехвата пакетов и выполнения манипуляций над ними),
сетевого стека Linux в целом, знаете о IP, UDP/TCP и т.д. и т.п.
Т.е. у вас есть знания о составных частях, но вы смутно представляете себе, как
из этого всего собрать, нечто, решающее сетевые задачи в комплексе.
Текст состоит из двух частей.
В первой части описаны предлагаемые принципы организации правил для фаервола (NETFILTER) и
управления трафиком (TRAFFIC CONTROL), а также взаимодействие этих подсистем.
Во второй части представлена и описана реализация фаервола на основе принципов, изложенных в первой части. Представлен и описан реально эксплуатируемый исходный код, который, посредством настройки и/или относительно легкой модифицикации, можно подстроить под конкретные нужды.
Если необходимо готовое, широко используемое решение - смотрите Shorewall http://www.shorewall.net (есть в большинстве дистрибутивов) или специализированные дистрибутивы-фаерволы/маршрутизаторы: IPCop, IPFire и т.п. (List of router or firewall distributions)
Если вы недостаточно понимаете возможности iptables - есть отличная документация по возможностям
и синтаксису, правда на английском -
"Iptables Tutorial", http://www.frozentux.net/iptables-tutorial/iptables-tutorial.html.
Есть русский перевод устаревшей версии: http://www.opennet.ru/docs/RUS/iptables/
Часть 1. Концепции
Что мы хотим
Условимся подконтрольные нам сети называть "внутренними сетями", а сети, которые не находятся под нашим управлением - "внешними сетями". В простейшем случае: все что в офисе - "внутренняя сеть", Интернет - "большая внешняя сеть".
В рассматриваемом случае шлюз выполняет роль фаервола, маршрутизатора и, возможно, на нём функционируют какие-либо сетевые сервисы.
Итак, есть общая задача - организовать одновременный доступ нескольких узлов (хостов, компьютеров, устройств) из внутренних сетей к сети Интернет через один публичный IP-адрес. Также, необходимо организовать инфраструктуру под собственные web/ftp/smtp/pop-сервера с возможностью доступа к ним из внешних сетей. Дополнительно, небходимо обеспечить возможность доступа к другим внешним сетям через дополнительные интерфейсы шлюза и доступ в сеть Интернет через второго провайдера.
Уточним требования к шлюзу и задачи которые мы хотим решить:
- задачи:
- организовать доступ из внутренних сетей к сети Интернет (и другим внешним сетям) через один публичный адрес (а-ля "чтобы все в офисе могли лазить по Интернету")
- в случае двух внешних сетей, имеющих выход в Интернет, маршрутизировать (направлять) исходящий трафик (согласно каким-то критериям) по разным путям (через разных провайдеров) (а-ля "чтобы Вася лазил в Интернет через провайдера X, а Петя, в то же время, через провайдера Y")
- контролировать доступ из внутренних сетей к узлам внешних сетей на уровне пользователей, адресов узлов, протоколов, tcp/udp-портов (а-ля "Петя может лазить везде,Васе только ICQ, а Маше вообще в Инете делать нечего")
- ограничивать скорость передачи данных между внешними и внутренними сетями (download и upload) на уровне пользователей, адресов узлов, протоколов, tcp/udp-портов (а-ля "Петя может качать со скоростью 100 кбайт/с, а Вася 200 кбайт/с")
- организовать доступ из внешних сетей к внутренним сетям с контролем доступа на уровне пользователей, адресов узлов, протоколов, tcp/udp-портов (а-ля "чтобы сотрудник мог подключиться к нашей сети из дома/командировки (через VPN)" и "чтобы люди могли заходить на наш сайт, почта была у нас и "ходила" от нас и к нам")
- требования:
- относительно простой визуальный анализ логики правил
- относительно простое (не требующее длительного анализа последствий, предсказуемое) внесение изменений в конфигурацию фаервола
- возможность перезапуска "по частям", т.е. чтобы при изменении конфигурации можно было обновлять не все правила, а только часть правил, соответствующих изменениям в конфигурации следующие требования относятся в большей степени к реализации как таковой:
- интеграция решаемых задач (контроль доступа и управление трафиком) в единое целое для упрощения администрирования и наглядности конфигурации
- желательно наличие конфигурационных файлов, позволяющих задать необходимые метаданные (имена узлов, ФИО сотрудников и т.п.)
Схема сети
Ниже приведена схема сети, которая будет рассматривать в дальнейшем:
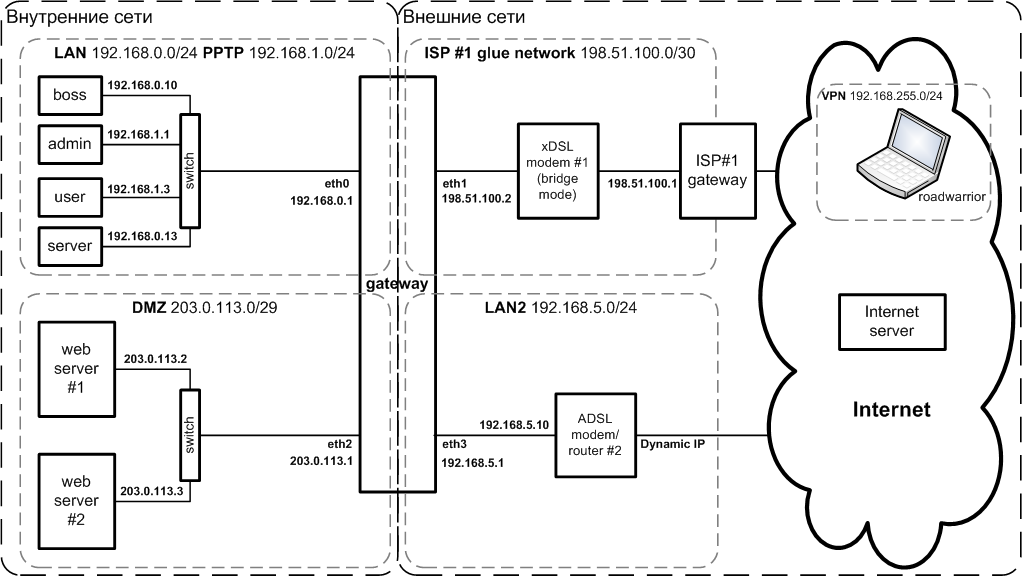
В общем, схема представляет собой классический "three-legged" ("Т-образный") firewall с выделением сервисов, доступных извне в отдельную сеть DMZ (от "Демилитаризованная зона"), которая подключена к отдельному интерфейсу (т.е. сетевой карте).
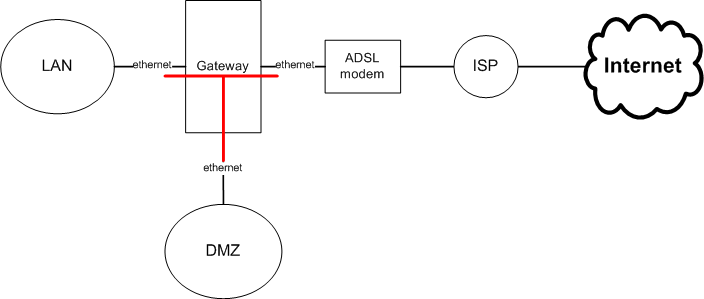
Чтобы лучше была видна "Т-образность" фаервола, ниже приведена слегка упрощенная схема (без подключения ко второму провайдеру).
Теперь рассмотрим схему сети на Рис.1 подробнее:
Территориально в Здании 1 расположены:
- LAN - наша локальная сеть, в которой расположено все наше оборудование (компьютеры), которое должно быть недоступно напрямую (по IP-адресам) извне;
- PPTP - виртуальная сеть поверх физичеcкой сети LAN - служит для контроля доступа из внутренних сетей во внешние: чтобы "выйти в Интернет" надо установить PPP-туннель к шлюзу;
- DMZ - демилитаризованная сеть, в которой расположено оборудование,
которое должно быть доступно извне (web/ftp/почтовый сервера).
Возможны два варианта: - сеть DMZ имеет публичные адреса выделенные провайдером - нужна только маршрутизация;
- сеть DMZ имеет private адреса - нужны: маршрутизация + SNAT + DNAT + port forwarding;
- ADSL модем №1, подключеный одним портом к шлюзу Gateway, а другим - к сети провайдера ISP1, например по телефонной линии;
- Gateway - собственно шлюз: компьютер с ОС Linux, 4-мя сетевыми интерфейсами (сетевыми Ethernet-картами). Шлюз выполняет роль маршрутизатора, фаервола, а также, на нем могут функционировать некоторые сервисы. Именно через него проходит весь трафик между сетями и именно здесь сосредоточены функции управления и контроля. На шлюзе:
- к интерфейсу eth0 через коммутатор (switch) подключена сеть LAN;
- к интерфейсу eth1 подключен (своим Ethernet-портом) ADSL модем №1, Интерфейс имеет статический IP-адрес, выданный провайдером ISP1;
- к интерфейсу eth2 через коммутатор (switch) подключен сеть DMZ;
- к интерфейсу eth3 через коммутатор (switch) подключена сеть LAN2;
Территориально в Здании 2 расположены:
- неподконтрольная, но доступная нам локальная сеть LAN2: нам выделен один адрес для подключения шлюза Gateway. Сеть LAN2 имеет выход в Интернет через ADSL модем №2
- ADSL модем №2, подключенный одним портом к сети LAN2, а другим - к к провайдеру ISP2 (например по телефонной линии). Внешний интерфейс имеет динамический IP-адрес, выдаваемый провайдером ISP2 при подключении. Есть возможность напрямую или через администратора сети LAN2 настраивать маршрутизацию на ADSL модеме №2;
- roadworrior - мобильные сотрудники, находящиеся вне внутренних сетей (командировка, дом) и желающие получить доступ в сеть LAN (и возможно в LAN2).
Почему рассматривается именно этот вариант схемы?
Естественно реальная сеть, являющася прототипом рассматриваемой здесь сети, развивалась от простого к более сложному. Сначала была сеть LAN и один провайдер ISP1. Далее потребовалось контролировать доступ из сети LAN в Интернет - был выбран PPTP и появились pppN интерфейсы. Затем появилась необходимость в размещении собственных сервисов - для этого появилась сеть DMZ. Позже появилось подключение к сети LAN2 и выход через неё на второго провайдера ISP2. Соответственно, росло и количество интерфейсов.
С другой стороны, рассматриваемый вариант удобен тем, что он имеет достаточную сложность, чтобы проявилась значительная часть вопросов и проблем, возникающих при управлении фаерволом на таком шлюзе.
Проблемы
Как организовать последовательность правил для фаервола? По какому принципу? Чтобы это было удобно и наглядно. В NETFILTER есть пять встроенных цепочек:
- INPUT - для всех входящих (через любой интерфейс) пакетов, предназначенных для данного узла (т.е. после процесса маршрутизации);
- OUTPUT - для всех исходящих через все интерфейсы пакетов ещё до процесса маршрутизации;
- FORWARD - для всех проходящих (из любого - в любой интерфейс) пакетов;
- PREROUTING - для всех входящих (через любой интерфейс) пакетов, ещё до процесса маршрутизации;
- POSTROUTING - для всех исходящих (через любой интерфейс) пакетов уже после процесса маршрутизации.
Чаще всего, в примерах и HOWTO встречается такой подход: правила фильтрации помещаются в эти цепочки "все в кучу" - одно за одним: все правила для фильтрации входящих пакетов на все интерфейсы - в INPUT, все правила для фильтрации исходящих пакетов из всех интерфейсов - в OUTPUT. Или: все разрешающие правила - в одну пользовательскую цепочку, все запрещающие - в другую цепочку. Или: все правила для tcp - в одну цепочку, для udp - в другую, для icmp - в третью и т.п. (см. тот же "Iptables Tutorial"). Изредка вводятся какие-то цепочки для решения каких-то частных задач и только. Достаточно универсальная методика не предлагается - в основном какие-то фрагменты, из которых трудно "сложить" что-то "внятное".
Такой подход к организации последовательности правил приводит к ряду сложностей:
- правила изначально трудно планировать и разрабатывать: неочевидно какого принципа придерживаться, какие правила должны идти раньше, какие - позже; со временем это 100%-но превращается в неуправляемый "бардак" и поэтому;
- правила трудно анализировать: выяснить (вспомнить) "что я тут накрутил?";
- правила трудно модифицировать: вам надо внести изменения, и для этого вам сначала надо вспомнить "что я тут накрутил?";, потом долго думать "куда же мне воткнуть эти новые правила?", а затем еще дольше анализировать: "будет ли это работать нужным образом после внесения изменений?" и "не нарушу ли я то, что раньше работало?";
- правила трудно автоматизровать: для бессиcтемных наборов правил труднее написать некий скрипт, автоматизирующий создание нужной логики на основе неких конфигурационных файлов.
Основные концепции: потоки, линки, цепочки
Косвенно о применимости данного подхода намекает cуществование "Strict Reverse Path Forwarding" в RFC 3704 - Ingress Filtering for Multihomed Networks:
Strict Reverse Path Forwarding is a very reasonable approach in front of any kind of edge network; ... First, the test is only applicable in places where routing is symmetrical - where IP datagrams in one direction and responses from the other deterministically follow the same path. While this is common at edge network interfaces to their ISP, it is in no sense common between ISPs, which normally use asymmetrical "hot potato" routing.
В целом, в RFC 3704, речь идет о защите от трафика с поддельных адресов путем проверки на маршрутизаторе маршрутизации до адреса-источника. Адрес-источника в получаемом пакете проверяется по FIB и если пакет был получен через тот же интерфейс, через который будет маршрутизироваться ответ к этому адресу, то всё ок. Иначе пакет можно игнорировать. Естественно это работает только при симметричной маршрутизации, которая используется при подключении клиента к провайдеру (т.е. наш случай).
- Потоком (flow)
-
условимся называть однонаправленный логический канал передачи данных между
двумя сетями или сетью и шлюзом. С учетом того, что:
- физически трафик между сетями проходит не напрямую, а через шлюз;
- в одну и ту же сеть (напр. INET) трафик может идти через разные интерфейсы шлюза;
- трафик в разные сети может идти через один и тот же интерфейс шлюза (напр. в LAN2 и INET через eth3),
- cеть источник,
- входной интерфейс на шлюзе,
- выходной интерфейс на шлюзе,
- сеть приёмник.
Далее по тексту потоки будут обозначаться следующим образом:
- сеть_источник>вх_интерфейс-исх_интерфейс>сеть_приёмник обозначает один конкретный поток. Например LAN>eth0-eth3>INET, LAN>eth0-GW;
- сеть_источник>сеть_приёмник обозначает все потоки (через все интерфейсы) между двумя сетями, идущие в одном направлении. Например LAN>INET, INET>GW;
- сеть_источник-сеть_приёмник обозначает все потоки (в прямом и обратном направлениях) между двумя сетями; Например LAN-INET, INET-GW.
- Из двух потоков, поток считающийся прямым, выбирается произвольно. Обратным же для прямого, будет поток, в идентификаторе которого входящие и исходящие сеть и интерфейс зеркально переставлены местами.
- Линком, связью (link)
- в данном тексте условимся называть совокупность всех потоков (прямых и обратных через все интерфейсы) между двумя сетями или сетью и шлюзом.
- Цепочкой потока (flow chain)
- будем называть пользовательскую цепочку, в которой сгруппированы правила, предназначенные для управления пакетами данного потока.
На рис.3 показаны основные потоки. Потоки относящиеся к одному линку имеют один цвет. Неиспользуемые или второстепенные потоки не показаны, чтобы не загромождать схему. Потоки между VPN и другими сетями показаны в разделе Функционирование VPN с точки зрения фаервола. Каждая стрелка соответствует потоку, а название стрелки - имени цепочки в правилах фильтрации.
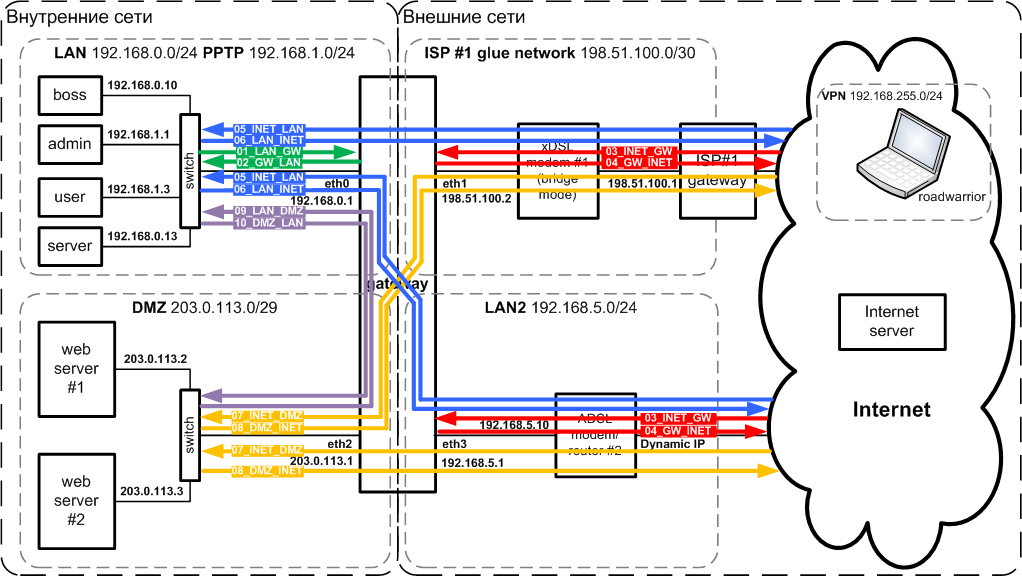
Из схемы видно, что, например, линк LAN-DMZ состоит из двух потоков:
- LAN>eth0-eth2>DMZ - прямого и
- DMZ>eth2-eth0>LAN - обратного.
- LAN>eth0-eth1>INET - прямой,
- LAN>eth0-eth3>INET - прямой,
- INET>eth1-eth0>LAN - обратный,
- INET>eth3-eth0>LAN - обратный,
- LAN>ppp+-eth1>INET - прямой,
- LAN>ppp+-eth3>INET - прямой,
- INET>eth1-ppp+>LAN - обратный,
- INET>eth3-ppp+>LAN - обратный.
В случаях когда сетью источником/приемником является сам шлюз,то входной/выходной интерфейсы не имеют смысла, например для линка LAN-GW:
- LAN>eth0-GW - прямой поток,
- GW-eth0>LAN - обратный.
Выше была показана только часть существующих между сетями потоков.
Посмотрим, сколько всего потоков в рассматриваемой конфигурации.
Представим схему сети в виде графа (рис. 4), в котором шлюз и сети представлены вершинами.
Соединим каждую вершину со всеми остальными - получим полный граф со всеми
возможными линками (ребра графа) между пятью сетями. Цвет линков на рис. 4
соответствует цветам на рис. 3. Серым цветом показаны неиспользуемые линки -
трафик между этими сетями нам не нужен и поэтому не разрешён.
Кол-во линков будет равно N*(N-1)/2, где N - кол-во вершин в графе.
Для рассматриваемой сети N=6 и кол-во линков равно 15.
Т.к. линк состоит как минимум из двух потоков - прямого и обратного, то
минимальное кол-во всех потоков будет равно 30.
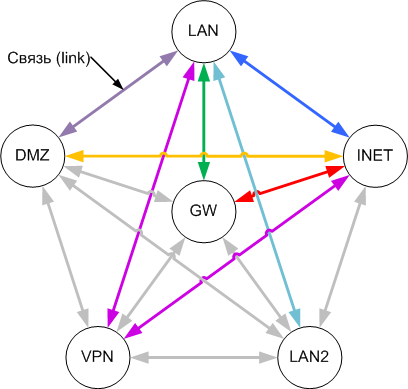
Однако это еще не всё. Сеть LAN у нас "синтетическая" и фактически объединяет две разных IP-сети на двух разных интерфесах - eth0 и ppp+. С сетью INET похожая ситуация - доступ в сеть INET тоже возможен через два интерфейса - eth1 и eth3. Поэтому если мы хотим посчитать абсолютно все варианты обмена трафиком, то граф должен содержать все сочетания сеть-интерфейс: LAN-eth0, LAN-ppp+, INET-eth1, INET-eth3, LAN2-eth3, VPN-tun1, DMZ-eth2, GW или что то же самое все интерфейсы шлюза плюс сам шлюз. Получаем 7 интерфейсов плюс сам шлюз и полное кол-во потоков 7*8=56. Максимальное же кол-во потоков для графа на рис. 3 будет равно 52, т.е. меньше на 4 потока: LAN>eth0-ppp+>LAN, LAN>ppp+-eth0>LAN и INET>eth1-eth3+>INET, INET>eth3-eth1>INET.
Теперь переходим к предлагаемому приниципу организации правил.
Основной подход в организации правил - вместо линейной последовательности правил использовать ветвление: каждому потоку - своя пользовательская цепочка (цепочка потока). Пакет "направляется на проверку" в ту или иную пользовательскую цепочку на основании принадлежности к одному из потоков.
Схематично это можно изобразить следующим образом:
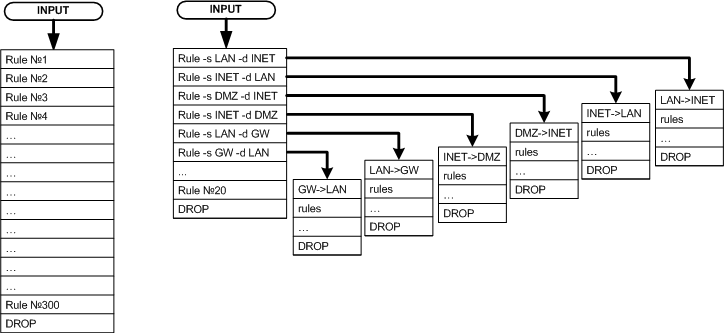
- идентифицируем все возможные связи между сетями и между сетями и шлюзом
- для каждого реально используемого соединения создаем по две (для прямого и обратного потока) отдельных цепочки с информативными именами
- правила, относящиеся к соответствующему потоку помещаем в соответствующую цепочку (т.е. в цепочку потока)
- во встроенных цепочках INPUT, OUTPUT, FORWARD создаем только правила переходов в соответствующие цепочки потоков
- используем данный подоход как для фильтрации (в filter table), так и модификации (напр. MARK, CLASSIFY) пакетов (mangle table)
В случае необходимости иметь единый набор правил для разных потоков достаточно направить пакеты, принадлежащие разным потокам, в одну и ту же цепочку потока. Например, в рассматриваемом примере, правила фильтрации одинаковы для трафика между сетями LAN и Интернет вне зависимости от того каким путём он идет: через eth0 или ppp+ и eth1 или eth3. Или, например, трафик между сетями LAN, PPTP и шлюзом GW будет обрабатываться одинаково, как будто LAN, PPTP - одна сеть.
Ниже приведены ссылки на листинги правил фаервола для данной схемы, которые будут рассматриваться далее по тексту.
Конфигурация интерфейсов из файла /etc/network/interfaces
/etc/network/interfaces allow-hotplug eth0 eth1 eth2 eth3 ### LAN auto eth0 iface eth0 inet static address 192.168.0.1 netmask 255.255.255.0 network 192.168.0.0 broadcast 192.168.0.255 ### INET auto eth1 iface eth1 inet static address 198.51.100.2 netmask 255.255.255.252 network 198.51.100.0 broadcast 198.51.100.3 gateway 198.51.100.1 ### DMZ auto eth2 iface eth2 inet static address 203.0.113.1 netmask 255.255.255.248 network 203.0.113.0 broadcast 203.0.113.7 ### LAN2 auto eth3 iface eth3 inet static address 192.168.5.1 netmask 255.255.255.0 network 192.168.5.0 broadcast 192.168.5.255
Какие плюсы и минусы имеет такой принцип организации правил? На мой взгляд следующие:
- сразу просматривается некая логика которой можно следовать на протяжении всего жизненного цикла фаервола;
- довольно легко разработать, анализировать и модифицировать правила - просто выбираем, по какому потоку мы хотим что-то сделать - и "лезем" только туда, практически не боясь затронуть логику, действующую по другим потокам; меньше вероятность ошибок - мы знаем, что в данной цепочке будут проверяться только пакеты относящиеся к данному потоку;
- появляется возможность легко выборочно перезапускать firewall, т.е. обновлять правила "на лету" только по выбранному потоку, не затрагивая остальные;
- предположу, что такая организация правил ускоряет проверку пакетов: вместо проверки пакета по линейному списку, состоящему из всех правил, происходит определение нужной группы правил на основании сетей и интерфейсов пакета и, как следствие, существенное сужение списка проверяемых правил; хотя тут многое зависит от того сколько проверок потребуется для данного конкретного пакета и от соотношения количества цепочек, определяющих принадлежность и количества правил в цепочках потоков;
- единственным "недостатком" можно считать то, что количество потоков быстро растет с увеличением количества интерфейсов на шлюзе и контролируемых сетей, однако этот вопрос легко решается автоматизацией - описываем сети, а скрипт создает нужные цепочки; 4-ре интерфейса, пожалуй, разумный максимум для полностью ручного написания и модификаций правил фаервола;
Фильтрация
Одна из основных задач фаервола - пропускать разрешенный трафик и блокировать нежелательный, т.е. фильтровать входящий, исходящий, проходящий трафик. Для правил фильтрации в NETFILTER есть таблица filter - именно в неё добавляются правила, если в команде iptables явно не указана желаемая таблица. Однако, технически, правила фильтрации можно размещать в любых таблицах. В этой части будут показаны реально используемые правила фильтрации, но сначала важно разобраться, какие сетевые сервисы могут присутствовать на шлюзе, а какие там совершенно неуместны.
Сетевые сервисы или чего не должно быть на шлюзе
Максимум, что можно допустить на шлюзе - аутентификация межсетевого доступа пользователей. И даже это желательно выносить на отдельный сервер аутентификации. Все сетевые сервисы потенциально уязвимы и через них шлюз может быть взломан и как результат - может быть получен контроль над шлюзом и доступ во все сети. Для уменьшения вероятности взлома шлюза через сетевые сервисы их (сервисы) выносят на отдельные узлы (серверы) в отдельную, частично изолированную, сеть - DMZ.
На шлюзе правила фильтрации настраивают таким образом, что подключения, инициируемые из сети LAN в DMZ - разрешены, а вот соединения инициируемые из сети DMZ в LAN - блокируются! Таким образом, при взломе сервиса, работающего на сервере в DMZ, уменьшаются последствия взлома - напрямую со взломанного сервера невозможно будет подключиться к изолированой сети LAN. Это и есть функция сети DMZ.
Однако в реальности, по разным организационно-финансовым причинам, не всегда есть возможность вынести сетевые сервисы (web/ftp/smtp/pop3/dns и т.п.) в отдельную сеть. Поэтому не остается ничего другого, как ставить их на единственном сервере - шлюзе.
Размещать (все) сервисы непосредственно на шлюзе можно, если вы считаете что риски, связанные с таким подходом, являются приемлемыми. Например, вы считаете вероятность взлома низкой, или потери от утечек и восстановления работоспособности не существенными.
Конкретно в нашем примере, сервисы расположены на шлюзе и только web-сервер вынесен в DMZ. Поэтому на шлюзе есть открытые порты.
Контроль доступа
Для контроля доступа на уровне адресов хостов, протоколов, tcp/udp-портов достаточно возможностей одного NETFILTER. Контроль сводится к фильтрации (блокированию) нежелательного трафика по IP и/или MAC адресам.
Но надо понимать, что и IP-адрес и MAC-адрес любого устройства в сети могут быть изменены на адреса, которым разрешен доступ в контролируемую сеть (т.е. подделаны). Таким образом контроль доступа только по адресам не является абсолютно надежным, но на практике часто этого достаточно. Для более надежного контроля надо использовать какие-либо варианты аутентификации и авторизации трафика, проходящего через шлюз. Для этого можно использовать VPN или более специализированные решение, например NuFW.
PPTP VPN
В качестве VPN довольно удобно использовать PPTP: сервер есть под Linux, а клиент встроен во все версии Windows.
Для выхода в контролируемую сеть (например из LAN в Internet), пользователь должен создать туннель между своим устройством (компьютером) и сервером PPTP на шлюзе. Для этого он должен пройти аутентификацию по логину/паролю: получить доступ в контролируемую сеть без аккаунта невозможно. Естественно на шлюзе правила фаервола запрещают прохождение пакетов c адресов 192.168.0.0/24 сети LAN в контролируемую сеть. Зато там есть разрешающие правила для клиентских адресов pptp-тунеллей 192.168.1.xxx. Если пользователь пройдет процесс аутентификации, то будет создан туннель между его компьютером и шлюзом. На стороне шлюза туннелю будет присвоен адрес 192.168.3.1, а клиентской части туннеля - некий адрес, привязанный к логину и задаваемый в например /etc/ppp/chap-config. Т.о. создается устойчивое соотвествие "пользователь" - "IP адрес туннеля" и на шлюзе появляется возможность управлять доступом и другими параметрами подключения на основе IP-адреса клиентской стороны туннеля с помощю NETFILTER. Т.е. контроль на шлюзе и в этом случае происходит "естественным способом" - по IP-адресам. Только в этом случае адрес "защищен от подмены" логином/паролем.
OpenVPN
Для тех же целей можно использовать и OpenVPN.
Можно отключить шифрование, уменьшив нагрузку на шлюз. Недостатком этого варианта
является необходимость установки OpenVPN-клиента на клиентское устройство.
Для мобильных устройств с определенными ОС это может быть проблемой.
Также см. Выбор VPN
NuFW
Работа NuFW основана на другом принципе. На firewall устанавливается Nufw-сервер, который принимает пакеты от клиентов. На этом же хосте (или на другом) ставится сервер аутентификации Nuauth. На каждом клиентском хосте (компьютере) ставится Nufw-клиент. Каждый пакет исходящий от клиента принимается Nufw-сервером и ставится в очередь в ожидании аутентификации. Об этом пакете информируется Nuauth, который, в свою очередь, запращивает у соответствующего Nufw-клиента аутентификационные данные. Nufw-клиент запрашивает прохождение данного пакета у Nuauth и если пакет авторизован - передает разрешение на Nufw-сервер, который и "пропускает" пакет.
Nufw для своей работы использует NETFILTER: пакеты, подлежащие авторизации, просто направляются в определенную userspace (пространство пользователя) очередь при помощи target NFQUEUE, т.е. в очередь которой управляет Nufw-сервер. В случае удочной авторизации пакета, Nufw-сервер просто реинжектит пакет из очереди обратно в сетевой стек. В реальности достатчно отправлять на на авторизацию только NEW-пакеты, а остальные будут контролироваться в рамках сединения с помощью conntrack.
Как и в случае с OpenVPN, необходимость установки Nufw-клиента может стать непреодолимым припятствием при использвании устройств с ОС, под которые не существует клиента. В первую очередь это относится к мобильным устройствам.
В 2012 году проект был в "дауне". На начало 2013 похоже проект "восстал из пепла" с новым именем - UFWI
NuFW более громоздок и на момент написания первоначального варианта фаервола не было бесплатного NuFW-клиента под Windows, поэтому в свое время был выбран вариант с PPTP VPN.
Цепочки фильтрации
Теперь рассмотрим непосредственно сами цепочки фильтрации и правила в них. Однако, в отличии от большинства руководств, вместо анализа последовательности команд iptables, мы будем анализировать непосредственно результат их работы, т.е. вывод команды iptables -nvL.
Как видно илз листинга, цепочки имеют "говорящие" имена и пронумерованы. Это позволяет легко ориентироваться в листинге таблицы filter. К тому же цепочки сгруппированы по потокам и всегда выводятся в предсказуемом порядке, что удобно. Рассмотрим эти цепочки.
INPUT, OUTPUT, FORWARD
Листинг начинается со встроенных стандартных цепочек INPUT, OUTPUT, FORWARD. В эти цепочки помещены правила, которые "определяют принадлежность" (по интерфейсам и адресам сетей) пакета к какому-либо логическому потоку и переключают логику дальнейших проверок на последовательность правил в пользовательской цепочке, соответствующей потоку. Пакеты, не соответствующие ни одному из правил в этих цепочках (пакеты не соответствующие ни одному из логических потоков) игнорируются. Достигается это установкой политик по умолчанию (см. Chain XXXX (policy DROP...) Порядок, в котором размещены правила в цепочках INPUT, OUTPUT, FORWARD, косвенно влияет на скорость обработки пакетов: первыми желательно размещать правила, под которые будет, предположительно, подходить основная масса пакетов.Наборы правил, сгруппированые по потокам в пользовательские цепочки, описаны далее в порядке номеров на схеме.
Таким образом, в дальнейшем (после правил в цепочках INPUT, OUTPUT, FORWARD ), пакет проверяется на соответствие только "своим" (относящимся только к данному потоку) правилам, а не всем подряд правилам, имеющимся в firewall'е. Это и даёт преимущества, указанные выше.
Примечание. В англоязычных источниках процесс проверки пакета на соответствие какому-то из правил так и описывается: будто бы пакет "движется" по набору правил, от правилу к правилу, "прыгает" в другие цепочки, "выпрыгивает" из них обратно и т.д. Насколько я понимаю, это условность - в реальности пакет никуда не "движется" (по набору правил), но так очень удобно описывать процесс, в котором ядро, для каждого пакета, перебирает правила, имеющиеся в firewall'e, проверяет, соответствует ли пакет данному правилу и решает что с эти пакетом делать: проверить следующее правило, переключиться (-j ИМЯ_ЦЕПОЧКИ) на другую последовательность (цепочку) правил проверки, принять пакет (-j ACCEPT) или отвергнуть его (-j REJECT/DENY) и т.п. Конечно, взаимосвязь между этапами обработки пакетов в сетевом стеке и таблицами/встроенными цепочками есть, но не более того. Я по тексту буду тоже "грешить" таким подходом, чтобы не ломать язык.
Далее рассмотрим цепочки потоков и наборы правил в них подробнее, ориентируясь по схеме на рис. 3.
Расцветка правил, соответствует цветам потоков на схеме.
01_LAN_GW, 02_GW_LAN: Локальная сеть - шлюз
Начнём со взаимодействия локальной сети LAN и шлюза Gateway. Для цепочки 01_LAN_GW мы "отбираем" только пакеты пришедшие из сети 192.168.0.0/24 на адрес 192.168.0.1 интерфейса eth0, а также пакеты пришедшие из сети 192.168.1.0/24 на адрес 192.168.3.1 любого ppp-интерфейса. Это соответственно правила №2 и №3 в цепочке INPUT. 192.168.3.1 - это адрес серверных концов всех ppp-туннелей, он одинаков для всех и устанавливается в /etc/pptpd.conf.Для цепочки 02_GW_LAN всё наоборот: пакеты уходящие с 192.168.0.1 eth0 в сеть 192.168.0.0/24 и пакеты уходящие со 192.168.3.1 любого ppp-интерфейса в сеть 192.168.1.0/24. Это и есть потоки между локальной сетью и шлюзом.
Примечание. Возможно, вам покажется, излишним указывать в правилах одновременно интерфейс и его адрес (или адрес сети), но это не так. Дело в том, что на любой интерфейс может прийти пакет с абсолютно любым адресом назначения (и отправителя тоже). Если вы укажите только имя интерфейса и не укажете IP-адрес(а), то даже пакет с адресом получателя, не совпадающим с адресом интерфейса, будет принят на дальнейшую обработку и может "проскочить" ваш firewall. Поэтому ни в коем случае нельзя полагаться на то что, раз у вас внутренняя сеть имеет адрес 192.168.0.0/24, то в ней не могут появиться пакеты с адресами принадлежащими другим IP-сетям. Такие ситуации могут возникнуть как в результате попыток обойти firewall так и в штатных режимах, например при маршрутизации (policy routing) или использовании туннелей (IPSec/NETKEY). Тоже самое относится и к отправляемым пакетам: например eth1 имеет адрес 198.51.100.2 но это не значит, что все пакеты отсылаемые провайдеру ISP1 через этот интерфейс обязательно будут иметь адрес отправителя 198.51.100.2. И уж тем более это очевидно в случае, когда интерфейс имеет несколько IP-адресов (да, интерфейс может иметь несолько IP-адресов одновременно).
Итак мы рассмотрели, какие пакеты попадают на проверку в цепочки 01_LAN_GW, 02_GW_LAN. Теперь посмотрим, что у нас в цепочке 01_LAN_GW. Первым же правилом мы отправляем пакет в цепочку со счетчиками 01_LAN_GW_CNT, в которой просто перечислены интересующие нас правила с пустым target (в соответствующенй команде нет ключа -j). Это правило идет самым первым, потому что иначе не будут считаться пакеты уже установленных соединений.
В 01_LAN_GW_CNT, у подходящих правил, счетчики увеличиваются на размер пакета и мы снова возвращаемся в 01_LAN_GW на второе правило. Все "счетчики" являются необязательными и если они вам не нужны - просты выкиньте соответствующие правила и цепочки. Вторым правилом мы принимаем все пакеты, относящиеся к уже установленным соединениям (т.е. те о которых уже "знает" conntrack). Это правило идет вторым и перед правилами, разрешающими подключения на определенные порты, потому что основная масса пакетов будет относиться к уже установленным соединениям. И поэтому нет смысла пакеты "прогонять" сначала через кучу правил для новых соединений и только потом ставить правило RELATED,ESTABLISHED. Следующее правило перекидывает нас в цепочку 01_LAN_GW_SKIP_OR_DENY, в которой мы помещаем правила, запрещающие прохождение каких-либо пакетов и правила, позволяющие сделать исключения из этих запретов. Такая комбинация практически универсальна и позволяет реализовать большинство вариантов запретов и исключений. Остановимся на этом моменте подробнее.
Рассмотрим пример, правда несколько искусственный. Итак, вам надо открыть доступ к порту tcp 873 для всей сети 192.168.0.0/24, за исключением хостов с адресами из диапазона 192.168.0.10-192.168.0.20, но некий узел 192.168.0.13, из этого запрещенного диапазона, тоже должен иметь доступ на tcp 873.
Ясно, что запрещающее правило (192.168.0.10-192.168.0.20 tcp dport 873 DROP) должно идти перед
разрешающим (192.168.0.0/24 tcp 873 tcp dport 873 ACCEPT). А теперь, как из запретного
диапазона исключить 192.168.0.13 tcp dport 873? Надо поставить это правило перед правилом
192.168.0.10-192.168.0.20 tcp dport 873 DROP. А если у нас будет много разных
запрещающих условий и исключений из них? Надо будет следить за порядком следования
этих правил и это будет слишком громоздко.
Поэтому удобнее разнести запрещающие и исключающие правила в разные цепочки
по нижеизложенному принципу.
Как мы уже видели, в основной цепочке потока 01_LAN_GW первым же делом мы принимаем (ACCEPT) все пакеты, относящиеся к уже установленным (RELATED,ESTABLISHED) соединениям. Таким образом, после этого правила, все проверки будут проводиться только над пакетами "в состоянии NEW" (ну еще может быть INVALID), что, по идее, экономит ресурсы. Поэтому далее идет "работа" только с "NEW-пакетами".
Далее проверка из 01_LAN_GW переходит в цепочку 01_LAN_GW_SKIP_OR_DENY, где первыми размещены все исключающие правила с target -j RETURN, а самым последним стоит правило направляющее проверку в список запрещающих правил 01_LAN_GW_DENY. Таким образом пакеты, подпадающие под исключения из запретов, "выскочат сухими" из 01_LAN_GW_SKIP_OR_DENY обратно в 01_LAN_GW, так и не дойдя до цепочки 01_LAN_GW_DENY. А пакеты, не соответствующие исключениям, уйдут на проверку в 01_LAN_GW_DENY и, возможно там и "умрут" (DROP). "Выжившие" (не подошедшие ни под один DROP) "выскочат" сначала в 01_LAN_GW_SKIP_OR_DENY, так как цепочка 01_LAN_GW_DENY закончилась, а затем и в 01_LAN_GW. И если эти пакеты не будут соответствовать разрешающим правилам (ля-ля-ля state NEW -j ACCEPT) в этой цепочке, они будут "убиты" самым последним правилом в цепочке 01_LAN_GW (DROP), которое, в некторой степени, является перестраховочным, но полезным. Оно скорейшим образом убъет "неугодный" пакет, не давая ему "выпрыгнуть" обратно в INPUT и "гулять" по остальным правилам пока его не DROP'нут по default'у.
Таким образом, достаточно универсальную логику для одного потока можно построить по следующей схеме:
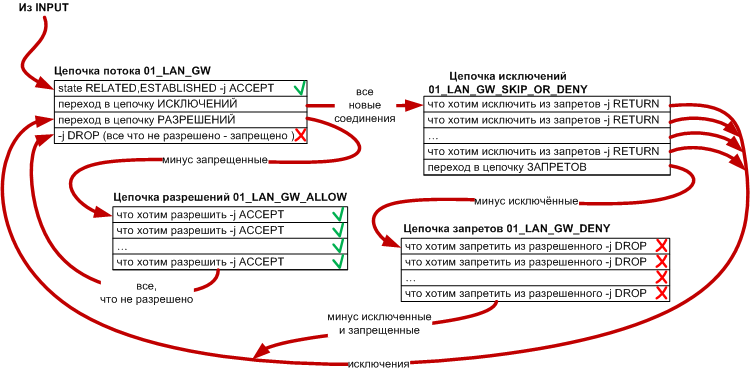
Т.е. разрешающие правила располагаются после всех запрещающе-исключающих правил.
Да, конечно можно, вместо использования цепочек LAN_GW_DENY и LAN_GW_ALLOW, просто выстроить правила в нужном порядке: сначала RELATED/ESTABLISHED, затем все запрещающие и затем все разрешающие - эффект будет (почти) тот же. "Почти" потому что, теряется возможность вносить исключения в запреты посредством добавления правил в LAN_GW_SKIP_OR_DENY - без использования цепочки подобный "пропуск" группы правил невозможен. Также теряется простой (путем очистки соответствующей цепочки) способ обновить часть правил: только разрешающие или только запрещающие. Т.е. возможности оптимизации зависят от наличия или отсутствия тех или иных правил в конкретном потоке. Эту задачу можно решить с помощью скриптов.
Назначение большей части открытых портов в 01_LAN_GW думаю очевидна. Специально поясню только два правила:
- tcp dpt:1723 - разрешаем подключения к демону pptp, так как контроль доступа из внутренних во внешние сети построен на использовании PPTP-туннелей
- proto 47 - он же GRE, в него упаковываются ppp-пакеты PPTP-туннелей, поэтому нам тоже его нужно разрешить; протокол GRE что называется stateless, поэтому нет особого смысла указывать state NEW. Здесь он указан, потому что правила созданы автоматически скриптом.
Теперь о цепочке 02_GW_LAN. Здесь мы описываем, что сам шлюз может посылать в сеть LAN. Здесь все тоже построено по вышеописанному принципу. Так же, вторым правилом после счетчиков, идет ... state RELATED,ESTABLISHED...ACCEPT, для того чтобы принимать пакеты ранее установленных соединенений.
Порты в 02_GW_LAN.
- tcp spt:5222, tcp spt:5223 - протокол XMPP; в сети LAN есть Jabber-сервер, на него шлюз отсылает некую информацию (оповещения от разных скриптов) со шлюза, которая оперативно видна в IM-клиенте
- tcp spt:20 - на шлюзе есть ftp-сервер (для технических целей), подключение к нему идет в active-режиме через SSL, поэтому модуль ядра ip_conntrack_ftp не сможет распознать в зашифрованном потоке служебную информацию FTP-протокола и отнести новое соединение, которое сервер пытается установить с клиентом, к состоянию RELATED; таким образом правило ACCEPT ... state RELATED,ESTABLISHED для таких соединений срабатывать не будет и выход только один: явно разрешить ftp-серверу подключаться c tcp порта 20 шлюза на любой адрес и порт сети LAN; см. схему для Active FTP, например здесь Active FTP vs. Passive FTP, a Definitive Explanation
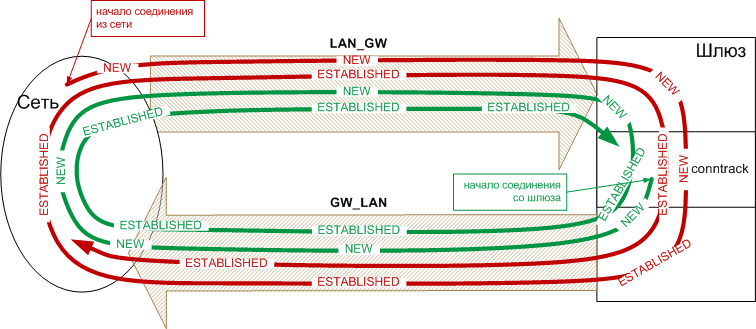
Почему RELATED,ESTABLISHED нужен в обоих направлениях
Помню, когда я начинал писать свои первые правила фаервола, я не до конца понимал, почему RELATED,ESTABLISHED нужен в обоих направлениях, даже если я разрешаю соединения только в одну сторону.
Чтобы лучше понять, почему, я рисовал диаграмки на бумажках, а здесь привожу следующую диаграмму. Думаю, с ней всё станет очевидно.
03_INET_GW, 04_GW_INET: Интернет - шлюз
Это потоки между самим шлюзом и сетью Интернет. Как видно из схемы, существует два пути для трафика между шлюзом и Интернетом: через провайдера ISP1 и через провайдера ISP2. Соответственно для проверок, в эту цепочку отбираются следующие пакеты (смотрим цепочки INPUT, OUTPUT):-
для пути через провайдера ISP1
- входящие на адрес 198.51.100.2 интерфейса eth1
- выходящие из интерфейса eth1 с адресом источника 198.51.100.2
- входящие на адрес 192.168.5.1 интерфейса eth3 не из сети 192.168.0.0/16 (в том числе не из сети 192.168.5.0/24)
- выходящие из интерфейса eth3 с адресом источника 192.168.5.1 не в сеть 192.168.0.0/16
Выданный провайдером ISP1, адрес 198.51.100.2 на eth1, является статическим, поэтому внешние сервисы (ftp/smtp/dns/pop3) "слушают" на этом адресе и интерфейсе. Именно этот адрес является "адресом шлюза в сети Интернет". А вот адрес 192.168.5.1 на интерфейсе eth3 является внутренним, а внешний адрес присваивается внешнему интерфейсу модема ADSL №2 динамически. Т.е. шлюз своим интерфейсом eth3 непосредственно в Интернете "не виден". Поэтому организовать на нем внешние сервисы возможно, но на практике это связано с различными проблемами, связанными как с динамическим адресом модема (обновление DNS, RR в обратной зоне для SMTP-сервера и т.п.), так и необходимостью использования DNAT на модеме для осуществления проброса портов (port forwarding) от модема на eth3 шлюза. Т.о., в нашем примере, для интерфейса eth1 надо открыть порты внешних сервисов, а вот для eth3 это делать не надо.
Поэтому, специально для трафика, приходящего из Интернета на eth3 сделана отдельная цепочка 03_INET_GW_ISP2, которая фактичеcки является копией 03_INET_GW, но без "NEW-правил". В ней мы только считаем и разрешаем трафик от уже установленных соединений.
Почему в INPUT в правиле для 03_INET_GW_ISP2 мы не указали destination 192.168.5.1? Это связано с тем опять же с маршрутизацией через двух провайдеров: на интерфейс eth3 могут приходить и пакеты с адресом назначения 198.51.100.2, а не только 192.168.5.1. Причины этого рассмотрены в разделе "Этапы прохождения пакета через NETFILTER"
Схема же построения правил в цепочках 03_INET_GW, 04_GW_INET совпадает со схемой правил в цепочках 01_LAN_GW, 02_GW_LAN и не имеет каких-то отличительных особенностей.
05_LAN_INET, 06_INET_LAN: Локальная сеть - Интернет
Переходим к рассмотрению несколько более интересной ситуации: трафик между локальной сетью LAN и сетью Интернет. Здесь также два пути прохода трафика: через провайдера ISP1 и провайдера ISP2.В данном примере цепочки 05_LAN_INET, 06_INET_LAN универсальны и служат для фильтрации по обоим маршрутам, т.е. правила фильтрации одни и те же для трафика через обоих провайдеров.
Эти цепочки используются для проверки следующих пакетов (смотрим схему и правила):
-
для трафика через провайдера ISP1:
- входящих из сети 192.168.0.0/24 в интерфейс eth0 и выходящих через eth1;
- входящих из сети 192.168.1.0/24 в любой ppp-интерфейс и выходящих также через eth1 (для хостов, получающих доступ в Интернет через ppp-соединение);
- входящих из сети 192.168.0.0/24 в интерфейс eth0 и выходящих через eth3 на адреса не из сети 192.168.0.0/16. Дополнительный контроль целевой сети нужен для того, чтобы отличить трафик идущий конкретно в сеть 192.168.5.0/24 (т.е. LAN->LAN2) от любого другого (подразумевается, что для локальных сетей выбраны адреса из диапазона 192.168.0.0/16)
- входящих из сети 192.168.1.0/24 в любой ppp-интерфейс и выходящих через eth3 на адреса не из сети 192.168.0.0/16 (принцип тот же).
Смотрим как устроена цепочка 05_LAN_INET. Принцип тот же, что и в цепочках, рассмотренных выше. Но есть некоторые отличия.
Первое отличие - наличие цепочки 05_LAN_INET_LIMIT. Если в цепочках "сеть-шлюз" органичение на скорость создания новых подключений ограничивалась непосредственно в разрешающем правиле, то здесь удобно иметь глобальные (на всю сеть LAN) ограничения. Поясню как это работает. Но сначало о том, что привело к появлению цепочки 05_LAN_INET_LIMIT.
Если в сети LAN появятся зараженные компьютеры, то с высокой вероятностью они станут рассылать спам и прочую ерунду посредством SMTP-протокола, напрямую подключаясь к различным SMTP-серверам в Интернете. Не полагайтесь на наличие антивируса: всегда найдется машина, не защищенная в данный момент антивирусом (сотрудник или клиент принес свой ноутбук) либо найдется вирус, который не дететктируется установленным антивирусом. 100%-ый выход один - заблокировать подключение на tcp 25 на сетевом уровне. Однако при этом пользователи сети теряют возможность отправлять почту через внешние SMTP-сервера посредством почтовых агентов. Если это не проблема для сотрудников и/или у вас в сети есть свой собственный SMTP-сервер (естественно с SMTP-аутентификацией для защиты от неавторизованной рассылки), то можно решить эту проблему и так. А можно поступить чуть менее жестко.
Можно вместо жесткого запрета, сделать исключения для некоторых, нужных вам серверов, например популярных почтовых сервисов. Как раз правила в 05_LAN_INET_SKIP_OR_DENY и разрешают доступ к 25 tcp портам некоторых почтовых сервисов. А в 05_LAN_INET_DENY есть запрещающее правило на dst tcp 25. Таким образом мы запрещаем подключения на 25 tcp порт всех хостов в Интернете за исключением перечисленных в 05_LAN_INET_SKIP_OR_DENY.
Второй вариант - лимитировать кол-во подключений на 25 tcp в единицу времени. Так как задача вируса или бота - разослать как можно быстрее и больше, то можно заблокировать слишком часто идущие попытки подключения на 25 tcp. Правда это подразумевает, что бот остылает одно (или мало) сообщений через одно подключение (SMTP-сессию).
Для этого можно воспользоваться модулями iptables limit, hashlimit или recent.
В нашем примере использован limit - разберем сначала его. В 05_LAN_INET_LIMIT первое правило говорит: "Разрешить новые подключения на tcp порт 25 не чаще 2-х раз в минуту для каждой комбинации "адрес источника-адрес приемника" и допускается "сжечь"(использовать) до пяти подключений без контроля (промежутка времени)".
Перескажу своими словами, как работает этот алгоритм:
в некий "счетчик" ("корзину" - bucket) емкостью (burst) 5, с постоянной частотой 2 раза
в минуту "капают" (поступают) разрешения ("билеты") на прохождение пакета (т.е. чтобы "корзина"
заполнилась "до краев" надо около 2,5 минут). После заполнения "до верху" разрешения уже не капают,
а ждут пока в "корзине" появится свободное место. Свободное место появляется при
выдаче разрешения на прохождение одного пакета: одно разрешение - один пакет.
Теперь, пусть клиент из сети пытается подключиться к 25-му порту 10 раз в течении 10 секунд
(отправить 10 "NEW-пакетов" за 10 секунд).
Произойдет следующее: накопившиеся в корзине 5 разрешений будут "мгновенно" использованы
и 5 подключений будут сделаны в кратчайшие сроки и корзина опустошится: разрешениий
на прохождение пакетов больше нет. Теперь оставшиеся 5 пакетов смогут уйти,
только если в корзине появятся разрешения для них (по одному на пакет): поэтому
клиенту для отправки следующего (6-го) пакета придется ждать пока в корзину "капнет" очередное разрешение.
А так как капают они по 2 в минуту, то чаще двух подключений в минуту
клиент уже сделать не сможет. Если он снизит частоту своих подключений ниже 2/мин,
то разрешения снова смогут накапливаться до 5 (емкости корзины).
http://en.wikipedia.org/wiki/Token_bucket
Подключения, идущие чаще 2/минуту, не будут разрешены первым правилом и проверка "проваливается" дальше: на второе и третье правила. Ну а третье правило просто "убивает" пакет, который бы привысил заданную частоту. А вот второе правило записывает в системный лог (и возможно выдает на консоль) сообщение, но тоже с частотой не превышающей определенной заданной. Дело в том что, если пакеты, не подпадающие под лимит будут идти с большой частотой, то в лог (и на консоль!) будут, с этой же частотой, добавляться записи о каждом пакете (а их может быть ОЧЕНЬ много). Для ограничения записи в лог используется тот же модуль limit. Т.е. в логе мы увидим запись не о каждом пакет, превысившим частоту предыдущего правила, а только о части, не превысившей ограничений команды ...-j LOG Таким образом мы можем ограничить частоту подключений до желаемой величины, практически не даваю боту из сети забивать ваш канал и "сильно беспокоить" SMTP-сервера. Однако соединения хоть и редко, но будут осуществляться. Вообще этот модуль служит для защиты от DOS-атак, когда не надо полностью блокировать доступ.
Можно применить оба похода одновременно, что и видно на примере: ограничены сервера, на которые можно пдключаться и частота, с которой к ним можно подключаться.
Вместо модуля limit можно использовать использовать модуль recent. Для этого вместо трех команд, приведенных в примере, можно использовать такие:
iptables -A 05_LAN_INET_LIMIT -p tcp --dport 25 -m recent --update --seconds 120 --hitcount 5 --name LAN_INET_25 --rdest \ -m limit --limit 1/min --limit-burst 5 -j LOG --log-prefix `LAN->INET_SMTP_limit: ' iptables -A 05_LAN_INET_LIMIT -p tcp --dport 25 -m recent --update --seconds 120 --hitcount 5 --name LAN_INET_25 --rdest -j DROP iptables -A 05_LAN_INET_LIMIT -p tcp --dport 25 -m recent --set --name LAN_INET_25 --rsource -j ACCEPTчто даст нам следующее
0 0 LOG tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:25 recent: UPDATE seconds: 120 hit_count: 5 name: LAN_INET_25_LOG side: dest limit: avg 6/hour burst 5 LOG flags 0 level 4 prefix `LAN->INET_SMTP_limit: ' 0 0 DROP tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:25 recent: UPDATE seconds: 120 hit_count: 5 name: LAN_INET_25 side: dest 0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:25 recent: SET name: LAN_INET_25 side: sourceи означает: "если с определённого адреса за 120 секунд или менее будет происходить более 5 попыток подключения" - "убивать" пакеты с этого адреса в дальнейшем до тех пор, пока частота не снизится до "не более 5-ти пакетов за 120 секунд". Это условие описывается двумя правилами, а не одним (подробнее читайте документацию recent)
Какой эфект даст recent в сравнении с limit? После момента превышения частоты и до её спада ниже заданного уровня recent полность болкирует трафик, а limit "цедит в час по чайной ложке" как указано в параметре --limit. Но в limit можно указать отслеживание лимита по комбинации "источник-приёмник", а у recent либо только "источник", либо только "примёник": c limit можно ограничить каждую пару IP (source-destination) в отдельности, а с recent - только всю сеть, как единое целое.
07_INET_DMZ, 08_DMZ_INET: Интернет - DMZ
Как уже говорилось ранее сеть DMZ предназначена для размещения внешних сервисов. В нашем примере часть сервисов расположена на самом шлюзе (хотя это и является плохой практикой!), а в DMZ расположены два web-сервера: один с адресом 203.0.113.2 и другой с адресом 203.0.113.3. Предполагается, что доступ к серверам в DMZ извне осуществляется только через провайдера ISP1 по внешнему адресу 198.51.100.2, по причинам, описанным в разделе Интернет - шлюз. Рассмотрим соответствующие цепочки.Ситуация похожа на рассмотренную "трафик между двумя сетями, идущий через шлюз". Смотрим на схему и листинг цепочек и видим, что для этих цепочек мы отбираем следующие пакеты.
-
Для пути через провайдера ISP1:
- входящие в интерфейс eth1 и выходящие через eth2 с адресом сети назначения 203.0.113.0/29;
- входящие из сети 203.0.113.0/29 на интерфейс eth2 и выходящие через eth1.
- входящие в интерфейс eth3 и выходящие через eth2 с адресом сети назначения 203.0.113.0/29;
- входящие из сети 203.0.113.0/29 на интерфейс eth2 и выходящие через eth3.
Принцип построения цепочек такой же как и в остальных. Особо можно отметить, что здесь контролируются не только входящие порты (т.е. на какие порты можно подключиться извне), но и исходящие порты: куда и на какие порты в Интернете могут подключаться сервера из DMZ.
Так же как и в цепочках сединения Интернет - шлюз, для входящих на eth3 через ISP2 пакетов создана специальная цепочка 07_INET_DMZ_ISP2, в которой нет разрешений для установления новых соединений из сети Интернет.
09_LAN_DMZ, 10_DMZ_LAN: Локальная сеть - DMZ
Основная особенность у этих цепочек - однонаправленность для новых соединений: хосты из сети LAN должны иметь возможность подключаться (устанавливать новые соединения) к хостам сети DMZ, а вот наборот: хосты из сети DMZ к хостам сети LAN - нет.Для этих цепочек мы отбираем пакеты:
- входящие в интерфейс eth0 из сети 192.168.0.0/24 и выходящие через eth2 с адресом сети назначения 203.0.113.0/29
- входящие из сети 192.168.1.0/24 на любой ppp-интерфейс и выходящие через eth2 с адресом сети назначения 203.0.113.0/29
Второй момент, на который можно обратить внимания - правила, где есть tcp spts:60000:61000.
Они связаны с протоколом FTP через SSL
(как и tcp spt:20 разделе Локальная сеть - шлюз).
Только приём с открытием 20 порта здесь "не пройдет" из-за active mode протокола FTP!
Ведь в этом случае мы будем вынуждены разрешить подключения из DMZ в LAN,
чего мы крайне не хотим!
Выход один - использовать пассивный режим (passive mode) в котором все соединения инициирует только клиент (см. Active FTP vs. Passive FTP, a Definitive Explanation). Для этого на серверах в DMZ надо сконфигурировать ftp-сервер на прослушивание фиксированного диапазона портов, на которые клиент будет подключаться для передачи данных. Вот как раз прохождение пакетов на этот диапазон портов и нужно будет разрешить на шлюзе в потоках LAN->DMZ.
Фильтрация и отслеживание соединений (connection tracking)
В рассматриваемом варианте организации правил используются возможности NETFILTER по отслеживанию состояния соединений (stateful packet inspection), что необходимо учитывать в ситуциях, подобной описанной ниже.
Пусть для некоего хоста в данный момент разрешено прохождение пакетов: установление новых соединений разрешают правила типа -m state NEW, а прохождение остальных пакетов этих соединений разрешаются правилами типа -m state RELATED, ESTABLISHED. Пусть, начиная с какого-то момента исчезает необходимость в разрешении трафика данному хосту: для него планируется полностью удалить все правила (удалить хост из конфигурации), а не просто запретить трафик, явно добавив запрещающие правила. При этом подразумевается, что после удаления всех, в т.ч. разрешающих, правил, обмен пакетами для данного хоста тут же станет невозможным.
Однако только удаления рарзрешающих правил в такой ситуации недостаточно. Т.к. остаются правила типа -m state RELATED, ESTABLISHED, то хост сможет получать/отправлять пакеты в рамках ранее установленных соединений до момента их разрыва: явного или по таймауту. Например, если в момент удаления из конфигурации хост загружал некий файл, то и после удаления правил хост сможет продолжать загружать данный файл, пока он полностью не будет загружен.
Чтобы одновременно с удалением правил для хоста из конфигурации сразу же блокировался и весь связанный с хостом трафик, необходимо либо явно удалить все соединения данного хоста из таблицы connection tracking, либо перед удалением хоста из конфигурации предварительно ввести для него запрещающие правила и дождаться разрыва всех соединений по таймауту и только потом удалять все правила.
Для удаления отслеживаемых соединений а также других манипуляций с соединениями необходима утилита conntrack из пакета conntrack-tools.
Для работы утилиты conntrack необходимо предварительно загрузить модуль ядра ip_conntrack.
modprobe ip_conntrack # загружаем модуль ядраИ далее, например, чтобы удалить все соединения, установленные хостом с адресом 192.168.1.3 надо выполнить команду:
conntrack -D -s 192.168.1.3По этой же причине, для того чтобы запрещающие правила действовали и на уже установленные соединения, их необходимо вводить перед RELATED, ESTABLISHED-правилами. См. цепочку 05_LAN_INET в листинге таблицы filter.
Если же вам достаточно запрета только новых соединений, то запрещающие правила оптимальней вводить после RELATED, ESTABLISHED для уменьшения кол-ва правил, по которым проверяется каждый пакет данного потока.
Маршрутизация (routing)
Маршрутизация - процесс в котором определяется путь, по которому пойдет трафик. Поэтому для любого исходящего трафика должен быть каким-то образом определен (задан) маршрут, каким он пойдет до цели.
Маршрутизацию осуществляет ядро Linux. Настраивается же маршрутизация командой ip из пакета iproute или коммандой route из пакета net-tools. route не позволяет управлять всеми аспектами маршрутизации в Linux и является, в принципе, устаревшей. Поэтому рассматривается управление только через команду ip.
Стоит отметить, что в примере рассмотрена только статическая маршрутизация (static routing), при которой автоматически не отслеживаются изменения топологии (связей между хостами) сети, и таблицы маршрутизации не изменяются автоматически в ответ на изменение топологии.
Один провайдер
Сначала, рассмотрим как происходит маршрутизация, без учета того факта, что в Интернет можно "попасть" и через ISP2 (eth3). Рассмотрим таблицу маршрутизации для нашего примера:
#ip route show 192.168.1.1 dev ppp1 proto kernel scope link src 192.168.3.1. 192.168.1.3 dev ppp2 proto kernel scope link src 192.168.3.1. 192.168.255.2 dev tun1 proto kernel scope link src 192.168.255.1. 198.51.100.0/30 dev eth1 proto kernel scope link src 198.51.100.2. 203.0.113.0/29 dev eth2 proto kernel scope link src 203.0.113.1. 192.168.5.0/24 dev eth3 proto kernel scope link src 192.168.5.1. 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.1. 192.168.255.0/24 via 192.168.255.2 dev tun1. default via 198.51.100.1 dev eth1.
Пройдемся по таблице. Тут все просто - адрес назначения пакета ищется в этой таблице: если адрес назначения в пакете совпал с адресом в таблице (в случае сети - если принадлежит данной сети), то пакет направляется через интерфейс, указанный в подходящей строке. Двух одинаковых адресов (хостов или сетей) в этой таблице быть не может, поэтому и двух путей (через разные интерфейсы) к одному хосту (или в одну сеть) здесь задать нельзя.
192.168.0.0/16
192.168.5.0/24
то адрес 192.168.5.1 соответствует обоим сетям, но выбран будет маршрут для 192.168.5.0/24 так как здесь префикс (сети) длиннее.
Итак, первые два маршрута в таблице говорят о том, что пакеты для хоста с адресом
192.168.1.1 надо доставлять через интерфейс ppp1, а для хоста 192.168.1.3 -
через ppp2.
Это PPTP-клиенты подключившиеся из сети LAN.
3-ий маршрут говорит что пакеты для хоста с адресом
192.168.255.2 надо доставлять через через интерфейс tun1.
Это виртуальный интерфейс сервера OpenVPN.
4-ый маршрут говорит что пакеты для сети с адресом
198.51.100.0/30 надо доставлять через интерфейс eth1.
Это glue-сеть между шлюзом и щлюзом провайдера с адресом 198.51.100.1.
5-ый маршрут говорит что пакеты для сети с адресом
198.51.100.0/30 надо доставлять через интерфейс eth2.
Это сеть DMZ, 203.0.113.1 - адрес интерфеса eth2 в этой сети.
6-ой маршрут говорит что пакеты для сети с адресом
192.168.5.0/24 надо доставлять через интерфейс eth3.
Это сеть LAN2, 192.168.5.1 - адрес интерфеса eth3 в этой сети.
7-ой маршрут говорит что пакеты для сети с адресом
192.168.0.0/24 надо доставлять через интерфейс eth1.
Это сеть LAN, 192.168.0.1 - адрес интерфеса eth1 в этой сети.
8-ой маршрут говорит что пакеты для сети с адресом 192.168.255.0/24 надо доставлять через шлюз (в сеть OpenVPN) 192.168.255.2 через интерфейс tun1.
И наконец 9-ый маршрут говорит что пакеты для которых не было найдено
подходящго маршрута (т.е. хоста/сети назначения)
доставлять через через интерфейс eth1 на шлюз ("via" - "через") 198.51.100.1.
Это шлюз провайдера ISP1, через который пакеты далее попадут в Интернет.
Это и есть маршрут "по-умолчанию" (default).
Собственно так пакеты, "предназначенные для Интернета", и "попадают в Интернет". Это просто пакеты, для которых ядро не знает, где расположена нужная сеть/нужный узел (потому что не все сети в мире подключены непосредственно к вашему шлюзу), и поэтому ему ничего не остается как направить их туда, "где находятся все остальные сети".
Все эти маршруты были добавлены в таблицу маршрутизации автоматически при инициализации интерфейсов на основании конфигурационной информации. В Debian это файл /etc/network/interfaces.
Поэтому, в случае одного провайдера вручную делать особо ничего и не надо, кроме как правильно сконфигурировать интерфейсы. При указанной выше конфигурации таблицы маршрутизации весь "Интернет-трафик" идет только через провайдера ISP1.
Два провайдера
В этом случае возникает несколько вариантов того какой именно трафик куда и когда направить:
- направить все исходящие соединения через одного определённого провайдера;
- направить исходящие соединения через двух провайдеров: часть соединений через одного провайдера, оставшуюся часть - через другого, согласно неким критериям;
- приём всех входящих соединений только через одного провайдера
- приём входящих соединений через двух провайдеров одновременно, используя разные публичные адреса
Например, самый простой случай - это использовать ISP1 и ISP2 попеременно, переключаясь между ними по необходимости. Для этого самое простое - менять в таблице маршрутизации маршрут по умолчанию с
default via 198.51.100.1 dev eth1на
default via 192.168.5.10 dev eth3где 192.168.5.10 адрес модема ADSL модем №2 в сети LAN2, который выполняет роль шлюза в сеть провадера ISP2 и далее в Интернет.
А что делать если мы хотим использовать оба канала одновременно?
Использовать то, что называется "policy routing" (марщрутизация по политикам) совместно с несколькими таблицами маршрутизации (множественные таблицы маршрутизации).
Policy routing
Policy routing - механизм позволяющий управлять маршрутизацией не только на основании адреса-назначения в пакете (как только что было показано выше), но и на основе других критериев.
Взглянем на всю картину в целом. В действительности, та таблица маршрутизации, которая была показана выше является всего лишь одной из существующих таблиц маршрутизации и называется она main. Есть еще две "встроенные" таблицы: local и default. И, к тому же, можно создавать дополнительные таблицы маршрутизации - до 252 таблиц. Итак можно создать несколько таблиц с разными наборами маршрутов. А вот для того чтобы, управлять, тем по какой из этих таблиц будет определятся маршрут для того или иного пакета и нужна routing policy database (RPDB) (база политик маршрутизации). Используя только команду route невозможно управлять всем этим механизмом - она позволяет манипулировать только маршрутами в одной определенной таблице - main. Для полноценного управления мрашрутизацией служит команда ip из пакета iproute2
RPDB имеет несколько вариантов селекторов (selector) и действий (action), которые позволяют нам указать ядру: вот c такими пакетами делай указанное действие. Например: пакеты, идущие с такого-то адреса маршрутизируй (т.е. определяй куда его послать) с использование вот этой таблицы или пакеты помеченные так-то - блокируй и т.д. Селекторы можно комбинировать. Ниже приведен пример RPDB:
#ip rule show 0: from all lookup local 32763: from all fwmark 0x4 lookup isp2 32766: from all lookup main 32767: from all lookup default
Номер до двоеточия - приоритет записи в базе , все что до слова "lookup" - селектор(ы) и последнее - имя таблицы маршрутизации. Например запись 32763 значит: для пакетов с любым ("from all") адресом источника и у которых отметка MARK равна 0x4 (просто число, которым мы помечаем определенные пакеты в NETFILTER), маршрут определять по таблице с именем "isp2". Т.е. в этой записи скомбинированы два селектора: "from" и "fwmark".
- записи (правила) в RPDB перебираются в порядке их приоритета (первое число в записи RPDB)
- если данный пакет соответствует селектору правила, то выполняется действие указанное в правиле
- если указанное в правиле действие окончательно определяет маршрут пакета, то правила, следующие за "сработавшим" перебираться для данного пакета уже не будут, иначе перебор правил продолжается
Например: если в правиле указана некая таблица маршрутизации, то производится поиск подходящего маршрута в этой таблице: если маршрут найден, то правила RPDB, следующие за "сработавшим" перебираться для данного пакета не будут (так как маршрут определен), а вот если в таблице маршрутизации не будет найдено ни одного подходящего маршрута, то перебор правил в RPDB будет продолжен.
Например если в базу, показанную выше, добавить такое правило#ip rule del from all fwmark 0x4 priority 32700 prohibitто мы получим вот такую таблицу
#ip rule show 0: from all lookup local 32700: from all fwmark 0x4 prohibit 32763: from all fwmark 0x4 lookup isp2 32766: from all lookup main 32767: from all lookup default
В ней для пакетов с одной и той же отметкой MARK сначала идет правило с запретом (prohibit), поэтому все пакеты, имеющие отметку MARK=0x4 будут запрещены. Для таких пакетов правило с приоритетом 32763 уже никогда срабатывать не будет, так как в правиле 32700 маршрут пакета однозначно будет определен (запрет) в процессе маршрутизации!
Или другой пример. Например если в базу добавить такое правило с таблице маршрутизации:#ip rule add from all fwmark 0x4 priority 32700 table newtableто мы получим вот такую таблицу
#ip rule show 0: from all lookup local 32700: from all fwmark 0x4 lookup newtable 32763: from all fwmark 0x4 lookup isp2 32766: from all lookup main 32767: from all lookup default
В этом случае, если в таблице маршрутизации newtable для пакета найдется подходящее правило, то правило с приоритетом 32763 тоже не сработает. А вот если в таблице newtable не найдется ни одного подходящего для данного пакета правила маршрутизации, то пакет далее будет проверяться на правило с приоритетом 32763.
Видов селекторов не так уж много (смотрите документацию), но один из них "убойный" - это fwmark.
fwmark: NETFILTER+routing
Селектор fwmark позволяет сделать одну, но очень мощную вещь: отбирать в правилах RPDB пакеты на основе меток, которые можно с помощью NETFILTER ставить в пакетах.
С помощью iptables мы можем "помечать" пакеты в таблице mangle. Тут важно знать что эти метки вставляются не внутрь пакета, а ассоциируются с пакетом, до тех пор пока пакет не ушел в сеть. Т.е. эти метки привязаны к пакету, но хранятся вне его - в памяти ОС и по сети не передаются. Метки существуют пока пакет "крутится" внутри операционной системы данного хоста (компьютера).
Еще важно помнить про разные типы меток, которые могут быть привязан к пакету одновременно и которые не надо путать между собой (CONNMARK, CONNSECMARK, MARK, SECMARK). Также важно не путать установку отметки (это определённые виды target'ов в ключе '-j') c проверкой на соответствие (match) между отметкой в пакете и заданной в правиле. Сейчас речь пойдет о отметках, которые проставляются у пакетов target'ом MARK.
Итак есть все элементы для решения задачи маршрутизации через двух провайдеров:
- возможность создать несколько таблиц маршрутизации
- возможность NETFILTER помечать нужные нам пакеты
- база политик маршрутизации, позволяющая задать правила (в том числе и через отметки в пакетах): какой трафик с помощью какой таблицы маршрутизировать
Теперь уточним, чего именно хотим добиться:
- общий принцип: каким путем трафик пришел (извне), таким и должен уйти и каким путём ушёл (из наших сетей) таким и должен вернуться;
- чтобы весь трафик между сетями LAN, DMZ и сетью Интернет шёл через провайдера ISP2 за исключением:
- rdp трафик (tcp 3389) должен идти через ISP1;
- VPN трафик между мобильными клиентами и сетью LAN должен идти через ISP1. Клиенты будут подключаться только через ISP1 на адрес 198.51.100.2, поэтому и уходить трафик должен через ISP1;
- трафик пользователя "user" (192.168.1.3) шёл через ISP1;
- чтобы весь трафик между шлюзом Gateway и сетью Интернет шёл через провайдера ISP2 за исключением:
- SMTP-сессии (tcp 25) должны идти через ISP1; это связано с тем, что сейчас многие SMTP-сервера проверяют не является ли адрес динамическим, проверяют по обратной зоне DNS, проверяют SPF и т.д. Поэтому, чтобы не иметь проблем с уходом почты с вашего SMTP-сервера, лучше чтобы трафик шёл со статического адреса, с правильно прописанной RR в обратной зоне;
- DNS-трафик (udp, tcp 53) должен идти через ISP1 - трафик критичный (для того же SMTP) и если "отвалится" ADLS модем №2, почта может не уходить из-за недоступности DNS. Поэтому DNS пускаем тем же путем, что и SMTP - через более надёжный канал через ISP1.
После старта ОС у нас уже есть автоматически сконфигурированная основная таблица маршрутизации "main". Она используется как основная для маршрутизации во все сети, подключенные к шлюзу.
#ip route show table main 192.168.1.1 dev ppp1 proto kernel scope link src 192.168.3.1. 192.168.1.3 dev ppp2 proto kernel scope link src 192.168.3.1. 192.168.255.2 dev tun1 proto kernel scope link src 192.168.255.1. 198.51.100.0/30 dev eth1 proto kernel scope link src 198.51.100.2. 203.0.113.0/29 dev eth2 proto kernel scope link src 203.0.113.1. 192.168.5.0/24 dev eth3 proto kernel scope link src 192.168.5.1. 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.1. 192.168.255.0/24 via 192.168.255.2 dev tun1. default via 198.51.100.1 dev eth1.
Теперь подготовим альтернативную таблицу маршрутизации, которую назовем "isp2". У этой таблицы только одна роль - определить другой "маршрут по умолчанию", отличный от того, который указан в таблице маршрутизации "main".
В файле /etc/iproute2/rt_tables описываем новую таблицу# # reserved values # 255 local 254 main 253 default 0 unspec # # local # #1 inr.ruhep 1 isp2 # таблица которую мы добавиливыполняем команды
#ip route flush table isp2 #route add default via 192.168.5.10 dev eth3 table isp2проверяем, что получилось
#ip route show table isp2 default via 192.168.5.7 dev eth3
Добавим новую политику в RPDB
#ip rule add from all fwmark 0x4 table isp2проверяем, что получилось
#ip rule show 0: from all lookup local 32763: from all fwmark 0x4 lookup isp2 32766: from all lookup main 32767: from all lookup default
Осталось сделать один шаг - пометить те пакеты, которые будут маршрутизироваться по таблице "isp2". Для этого надо разобраться с еще одним важным вопросом - где и каким образом помечать нужные пакеты.
Этапы прохождения пакета через NETFILTER
Открываем листинг команды 'iptables -t mangle -nvL', чтобы было удобнее следить за дальнейшими пояснениями.
Ниже приведена схема этапов (таблицы и цепочки) которые проходит пакет. Информация о этапах взята отсюда: http://www.frozentux.net/iptables-tutorial/iptables-tutorial.html#TRAVERSINGOFTABLES
На схеме показаны таблицы и цепочки, которые проходит трафик, маршрутизируемый с помощью таблиц "main" и "isp2" (пунктирное ответвление), точки в которых осуществляется пометка пакетов (MARK) и преобразование адресов (SNAT).
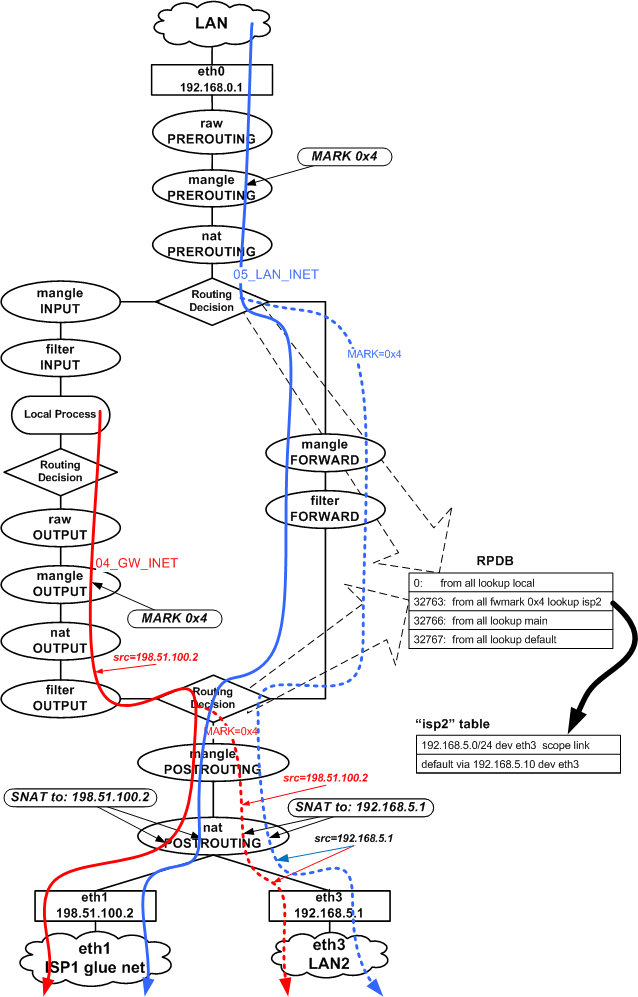
Поток GW->INET (цепочка 04_GW_INET_MARK в mangle)
Исходя из сказанного, помечаем нужные нам пакеты трафика Gateway<->Internet
в mangle OUTPUT. Почему, например, не в mangle POSTROUTING? Отметку надо проставить
еще до процесса маршрутизации (routing decision), чтобы на момент
осуществления маршрутизации нужные пакеты уже имели нужную метку.
Пометка в mangle POSTROUTING просто не будет иметь никакого эффекта.
Таким образом,согласно правилу from all fwmark 0x4 lookup isp2 в RPDB, трафик c отметкой 0x4, на финальном этапе маршрутизации будет направлен в eth3. По пути будет сделано преобразование адресов (SNAT to:192.168.5.1) и после этого трафик через eth3 уйдет в сеть LAN2 на шлюз 192.168.5.10. При этом пакет будет иметь: адрес источника 192.168.5.1, адрес назначения - адрес в Интернете и MAC-адрес назначения - MAC-адрес внутреннего порта ADSL модема №2 Таким образом, пакет будет доставлен в ADSL модем №2, откуда он, согласно маршрута по умолчанию модема, отправится к провайдеру ISP2.
Посмотрим на соответствующие правила (помечены красным) в листинге таблицы mangle.
В OUTPUT для eth1 есть переход в цепочку 04_GW_INET_MARK.
Там первые три правила, исключают из маркировки исходящий SMTP и DNS трафик.
Это сделано для того чтобы трафик почтового сервера всегда уходил со статичного адреса,
для которого прописана адрес в обратной зоне (.in-addr.arpa), так как очень часто
принимающий SMTP-сервер использует обратную зону для проверки истинности адреса
принимающего SMTP-сервера (Forward-confirmed reverse DNS).
DNS тоже не помечается, чтобы идти через более надежного провайдера ISP1.
Предпоследнее правило в цепочке помечает все новые исходящие от шлюза соеденения (CONNMARK) неким произвольным числом (0x500). Ну и последнее правило уже все пакеты соединений, помеченных этим числом (match 0x500), помечает числом 4 (MARK xset 0x4).
Т.е. помечать надо только трафик, относящийся к исходящим со шлюза соединениям, а весь остальной трафик через eth1 должен остаться нетронутым.
Поток LAN->INET (цепочка 05_LAN_INET_MARK в mangle)
С трафиком LAN<->Internet поступаем также, только в этом случае существует
возможность пометить трафик раньше - еще до первого решения о маршрутизации - в
mangle PREROUTING. Т.о. уже в цепочке FORWARD у помеченных пакетов будет
"правильный" выходной интерфейс источника eth3, а не eth1.
Смотрим листинг (правила помечены синим): там тоже есть исключения.
Первое исключение для подсети 198.51.100.0/30 - эта сеть подключена напрямую к eth1
и трафик в нее всегда должен идти через eth1.
Второе исключение для пользвателя в сети LAN с адресом 192.168.1.3 - ему надо "ходить"
через ISP1.
Третье исключение для сети DMZ - ответный трафик из DMZ должен всегда
уходить через eth1, так как входящие соединения приходят на eth1 (публичный статический адрес).
Четвертое исключение для подсети 192.168.255.0/24, выделенной для клиентов OpenVPN - ответный трафик также должен всегда уходить через eth1, так как openvpn принимает входящие соединения на eth1.
Пятое исключение для RDP (tcp 3389) трафика.
Далее, как и в случае 04_GW_INET_MARK помечаем новые исходящие соединения и уже только помеченные соединенения метим числом для дальнейшей маршрутизации по таблице isp2.
Далее смотрим как идет обратный трафик.
Потоки INET->GW, INET->LAN (цепочки 03_INET_GW, 06_INET_LAN в mangle)
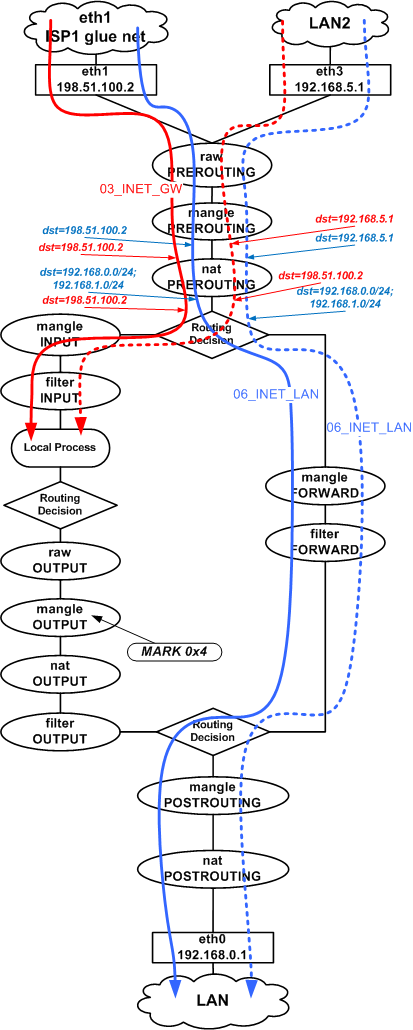
Пожалуй самое примечательное здесь это то, что в filter INPUT могут появляться пакеты вот с такими адресами назначения:
host [361.745891] IN=eth3 OUT= SRC=213.180.204.190 DST=198.51.100.2 LEN=52 TOS=0x08 PREC=0xC0 TTL=55 ID=6076 DF PROTO=TCP SPT=80 DPT=44909 WINDOW=13387 RES=0x00 ACK FIN URGP=0 host [361.917213] IN=eth3 OUT= SRC=217.14.203.229 DST=192.168.5.1 LEN=40 TOS=0x08 PREC=0xC0 TTL=55 ID=38988 DF PROTO=TCP SPT=80 DPT=54684 WINDOW=6456 RES=0x00 ACK FIN URGP=0
Ответные пакеты (рис. 9), приходящие на eth3 подвергаются обратной трансляции адресов и уже после nat PREROUTING и до самых Local Process пакеты будут иметь in=eth3 dst=198.51.100.2.
В процессе маршрутизации исходящего трафика из "общего потока" "вычленяется" трафик, который мы хотим направить через eth3: поэтому "дополнительный поток" (пунктир) появляется только в процессе маршрутизации.
Входящий же через eth1 и eth3 трафик "не сливается" после маршрутизации, так как входные интерфейсы у пакетов остаются разными на всем пути до интерфейса eth0.
С трафиком Internet<->DMZ (на рис. 8 и рис. 9 не показан) происходит то же, что и с трафиком LAN<->Internet, за исключением отсутствия преобразования адресов.
Входящий трафик через двух провайдеров
Рассмотрим для нашей схемы случай, в котором мы хотим принимать входящие соединения на веб-сервер в сети DMZ через два подключения ISP1 и ISP2 одновременно (не путайте этот случай со случаем использования двух каналов (основной+резервный) к одному провайдеру). Это возможно в случае, если клиенты будут подключаться на два разных IP-адреса, принадлежащих разным провайдерам. Пакеты от клиентов, подключающихся на адрес 203.0.113.2, будут проходить через провайдера ISP1 на eth1 и далее через наш шлюз в сеть DMZ. Пакеты от клиентов, подключающихся на внешний адрес модема ADLS №2,будут проходить через провайдера ISP2.
Так как на модеме ADLS №2 включен NAT и публичный адрес присваивается интерфейсу самого моддема, то клиенты, подключающиеся на этот адрес, будут соединяться с модемом, а не с веб-сервером в сети DMZ. Для того чтобы "пробросить" входящие соединение через модем до веб-сервера в сети DMZ, надо на модеме включить и настроить "проброс портов" (port forwarding). С этой функцией входящие соединение на определённый tcp или udp порт модема, будут перенаправляться далее на IP-адрес, в указанный настройке port forwarding'а. Дополнительно в таблице маршрутизации модема надо прописать путь до сети DMZ через 192.168.5.1, иначе "проброшенный" трафик модем будет направлять обратно в Интернет, так как у него этот трафик будет маршрутизироваться согласно маршруту по умолчанию, т.е. обратно через ISP2. Однако одного этого недостаточно для чтобы сервер в сети DMZ мог работать с клиентами, подключившимися через разных провайдеров.
Дело в том, что сервер, получив пакет от клиента, будет посылать ответные пакеты только через того провадера, чей шлюз прописан в маршруте по умолчанию. В зависимости от используемых протоколов и особенностей написания клиента, это может вызвать проблемы при обработке ответных пакетов у клиентов, к которым ответный трафик будет посылаться через другой интерфейс, а не через тот на который клиент отправлял пакеты серверу.
Это обусловлено тем, что клиент будет посылать пакеты серверу на один IP-адрес (в данном случае на внешний адрес ADLS-модема №2), а получать ответные пакеты с совершенно другого IP-адреса (в данном случае с адреса eth1). Большинство же реальных программ не рассчитаны на это, так как написаны с использованием такой абстракции транспортного уровня как internet socket.
В этой абстракции рассматривается передача трафика между двумя конечными точками соединения - сокетами, каждый из которых характеризуется комбинацией IP-адреса, порта и протокола (напр. TCP или UDP), где порт фактически идентифицирует приложение, создавшее сокет. Абстракция сокетов реализована в большинстве операционных систем и является стандартом де факто для написания приложений работающих с сетью Интернет. Т.о. именно ОС "занимается" учётом и идентификацией сокетов и соединений. Для сокетов с поддержкой соединения (TCP/SCTP), соединение однозначно идентифицируется парой сокетов: серверным и клиентским. Для сокетов без соединений (UDP), соединение однозначно идентифицируется локальным сокетом.
Из этого следует, что при использовании протоколов с поддержкой соединений, операционная система будет всегда ожидать прихода ответных пакетов с того сокета (т.е. IP-адреса:порта), с которым соединение было установлено изначально. Т.о. ответные пакеты, проходящие к клиенту с другого IP-адреса, ОС клиента не сможет отнести ни к одному из уже существующих сокетов и установленных соединений и просто их проигнорирует. Это справедливо для любых протоколов, работающих поверх TCP.
Для голого IP-протокола или для UDP такого ограничения нет - в принципе ничто не запрещает написать такой клиент и сервер, которые смогут получать и обрабатывать пакеты, приходящие с адресов, отличных от того, куда был отправлен или откуда был получен ответный первый пакет.
http://tools.ietf.org/html/rfc3704#page-5
Т.к. протокол HTTP реализован поверх TCP, HTTP-клиент не сможет работать с веб-сервером, который принимает входящие пакеты на один IP-адрес, а ответные пакеты отправляет этому же клиенту с друого IP.
Пока я вижу только один универсальный способ добиться этого - использовать модуль conntrack. Надо пометить все входящие в DMZ соединения с помощью CONNMARK: пакетам, входящим в разные интерфейсы, надо присваивать разные отметки.
Т.о. и ответные пакеты от серверов DMZ также будут иметь отметки, соответствующие тем отметкам, что были проставлены для входящих пакетов. Благодаря этому становится возможным по этим отметкам с помощью policy routing маршрутизировать ответный трафик через тот интерфейс, через который трафик вошёл.
Резервирование и переключение: динамическая маршрутизация?
todoДоступ из внутренних сетей к сети Интернет через один публичный адрес (NAT - трансляция адресов)
При прохождении трафика через маршрутизатор из одной сети в другую могут иметь место два случая:
- при прохождении пакетов через маршрутизатор никаких преобразований адресов не осуществляется
- при прохождении пакетов через маршрутизатор происходит преобразование (трансляция) адресов (NAT) согласно какому-то принципу
Например (см. рис. 3) пакеты из сети LAN в сеть DMZ проходят шлюз без преобразования адресов: пакет от хоста 192.168.0.1 доходит до хоста 203.0.113.2 с неизменённым адресом отправителя. Т.е. узел 203.0.113.2 "видит", что пакет пришел от хоста адреса 192.168.0.1, который, естественно, находится в другой IP-сети. Поэтому, когда узел 203.0.113.2 отошлет (ответный) пакет, то в качестве адреса получателя будет указан адрес 192.168.0.1 - пакет будет смаршрутизирован на нужный интерфейс (eth0) и попадет на узел 192.168.0.1.
В случае, когда по какой-либо причине такая "естественная" маршрутизация невозможна
(нежелательна), применяется трансляция адресов. Например, это невозможно в случае,
когда нужен доступ из сети с приватными адресами в сеть Интернет - так устроена (организована) адресация.
Пакеты с приватными адресами глобально (в рамках всей сети Интернет) не маршрутизируются.
Приватные адреса специально выделены для этих целей (локальных сетей).
Таких сетей великое множество и какая из них имеется ввиду в очевидно невозможно
определить в принципе.
Поэтому, даже если в сторону провайдера от вашего шлюза пойдут пакеты с приватными
адресами источника, то дойдут они не далее чем до первого маршрутизатора - там они и "умрут".
И по этой же причине пакет, посланый неким сервером клиенту с приватным
адресом, просто не дойдет до клиента.
В нашем случае, для трафика между сетями LAN и Internet необходимо применить NAT, а точнее Source NAT: адрес-источник во всех пакетах (например src 192.168.0.1), перед "выходом" через eth1 должнен быть заменен на адрес 198.51.100.2 (публичный адрес выданный нам провайдером ISP1). При этом все пакеты, отправляемые из сети LAN "будут выглядеть для Интернета" как отправленные одним хостом с публичным адресом 198.51.100.2.
Когда некий сервер, в ответ на приход такого пакета, ответит своим пакетом, то в адресе назначения будет указан 198.51.100.2 (а не, например, 192.168.0.1). Как же он, в конце концов, дойдет до хоста 192.168.0.1, ведь в ответ на пакеты с разными адресами (192.168.0.1,192.168.0.138 и т.д.) сервер будет отвечать на один и тот же адрес 198.51.100.2?
Для этого NETFILTER, помимо смены адреса источника, также меняет некоторые параметры отправляемых пакетов и ведет таблицы соответствия параметров исходных и модифицированных пакетов. Поэтому любой приходящий на 198.51.100.2 пакет NETFILTER может проверить на соответствие в этой таблице и "выяснить" относится ли пришедший пакет к соединению, установленному с хоста сети LAN (здесь также задействован модуль conntrack). Для TCP/UDP пакетов NETFILTER кроме адреса источника дополнительно заменяет порт источника на определённое значение, что и позволяет транслировать номер порта назначения в ответном пакете в адрес сети LAN. В случае протоколов, не имеющих портов, NETFILTER применяет (какие-то) другие (отличные от замены номеров портов) методики сопоставления адресов.
Также, есть ещё один путь прохождения трафика между сетями LAN и Internet - через eth3. Здесь преобразование адресов не является обязательным, так как оно все равно обязательно произойдет позже - в ADSL модеме №2. Хотя наличие NAT для этого трафика имеет свои преимущества: например не надо будет в таблицах маршрутизации хостов сети LAN2 (того же ADSL модема №2 или например принтеров) прописывать маршруты в сети 192.168.0.1 и 192.168.1.1 что облегчает адинистрирование и позволяет пользоваться устройствами сети LAN2, не поддерживающими настройку маршрутов, из сети LAN.
Теперь посмотрим как это сделано в нашей схеме.
Открываем листинг команды 'iptables -t nat -nvL'.
Как видно из рис.6 SNAT удобнее всего сделать в nat POSTROUTING.
В листинге это первое правило в цепочке POSTROUTING и оно означает: у всех пакетов,
выходящие через eth1, кроме идущих из сети 203.0.113.0/29 (т.е. из DMZ)
заменить адрес источника на адрес 198.51.100.2, что и требуется.
Второе правило в цепочке POSTROUTING задает трансляцию адресов для трафика, идущего через eth3: здесь мы заменяем адрес источника на адрес интерфейса eth3 только у тех пакетов, которые должны были идти на eth1, а мы "завернули" их при помощи policy routing на eth3. Как минимум часть таких пакетов (например, от локальных процессов) будут иметь адрес 198.51.100.2, а не нужный нам 192.168.5.1. Хотя, повторюсь, можно сделать преобразование и у абсолютно всех исходящих пакетов или только у пакетов у которых адрес источника не равен 192.168.5.1 - для решения задачи "расшаривания Интернета" эти варианты эквивалентны.
Однако, при необходимости надо учитывать влияние преобразования на связь между другими сетями: выборочная или поголовная трансляция пакетов перед выходом через eth3, будет влиять на доступность хостов сетей LAN и LAN2 между собой. Например, если будут транслироваться все пакеты, то связь из сети LAN с устройствами сети LAN2 будет работать независимо от наличия маршрутов в сети 192.168.0.1 и 192.168.1.1 в таблицах маршрутизации устройств сети LAN2. При этом, в обратном направлении (из LAN2 в LAN), без специальных ухищрений (напр. port forwarding ), невозможно будет "достучаться". Если же NAT будет выборочный (напр. как в нашем случае), то с устройствами в LAN2, у которых не заданы маршруты в сети 192.168.0.1 и 192.168.1.1 из сети LAN работать будет невозможно.
Вообщем с помощью этих двух правил мы и добъемся нужного эффекта: хосты из сети LAN смогут "лазить в Интернет через один белый адрес".
Управление трафиком (traffic control: shaping, policing и т.д.)
Раcсмотрим основные концепции управления трафиком (traffic control) в Linux.
Traffic control в Linux включает в себя три главных компонента:
- qdisc - дисциплины очереди, т.е. доступные в ядре типы планировщков для очередей сетевых пакетов;
- class - классы позволяют задавать "внутри" дисциплины сложные, иерархические настройки по ограничению пропускной способности;
- filter - позволяют классифицировать пакет, т.е. сопоставить пакет и класс, согласно правилам которого он будет обрабатываться в очереди;
Управление исходящим трафиком: shaping, scheduling
Начнём с исходящего трафика. В случае шлюза, исходящий трафик может быть сгенерирован как локальными процессами так и в результате прохождения трафика (forwarding) через шлюз, от одного сетевого интерфейса к другому. С каждым сетевым интерфейсом связана очередь (queue), в которую пакеты ставятся перед отправкой: пакет, который должен быть отправлен, отправляется в сеть не сразу, а ставится в очередь ("привязанную" к исходящему интерфейсу) и затем извлекается из очереди планировщиком для отправки в сеть согласно некому принципу (алгоритму).
- shaping - задержка отправки (определённых) пакетов из очереди в сеть для ограничения скорости передачи или сглаживания неравномерности передачи и
- scheduling - реорганизация порядка (приоретизиация) пакетов в очереди, т.е. управление порядком обработки (отправки в сеть) пакетов из очереди.
В traffic control для обозначения исходящяго трафика или исходящей qdisc используется термин egress (например egress qdisc). В команде же tc для задания исходящей дисциплины используется ключевое слово root, а не egress; например:
tc qdisc add dev eth0 root handle 6: htb r2q 5
Например, пусть в нашей схеме, два хоста сети LAN получают пакеты из сети Internet (что-то качают). Для определенности пусть пакеты проходят через eth1 далее они форвардятся на eth0 - естественно сначала они попадают в очередь этого интерфейса. В этой очереди единовременно могут находиться пакеты предназначенные для обоих качающих хостов.
Естественно, чаще всего, интересуют формулировки вида:
- "чтобы Вася мог качать со скоростью не меньше XXX Кбайт/с, но не больше YYY Кбайт/с" и одновременно с этим
- "чтобы Петя мог качать со скоростью не меньше ZZZ Кбайт/с, и если ему надо, автоматически, он мог повышать скорость скачивания до максимума, отбирая пропускную способность у других таких 'вась' "
Эти вопросы (и все другие вопросы связанные с управлением трафиком) решаются описанными принципами управления очередей и планированием: желаемые пропускные способности для каждого из хостов, их изменения в реальном времени в зависимости от неких приоритетов, а также пропускные способности задействованных каналов - все это взаимосвязано и для построения системы работающей ожидаемым и предсказуемым образом, надо в первую очередь, знать какого именно поведения вы хотите добиться от системы в целом.
Например, на рассматриваемой схеме (пока отбросим провайдера ISP2) пропускная способность подключения к ISP1 (пусть 1 Мбит/с=125 кбайт/с) распределяется между всеми хостами сетей LAN и DMZ, а также самим шлюзом. Допустим пользователей в сети LAN хотя бы 10 - на каждого придется по 12,5 кбайт/с чего явно мало даже для комфортного серфинга по Инету. А ведь есть еще сервера в сети DMZ и сам шлюз, которым тоже надо что-то выделить из 1 Мбит/с. Если все это распределить и установить вычисленные жёсткие лимиты, то каждому хосту достанется мизерные пару кбайт/с, которые ни один узел не сможет привысить, даже если остальные хосты не качают (и как следствие - канал свободен). Поэтому, возникает желание установить некие более высокие лимиты, но в то же время они не должны давать возможность какому-либо хосту единолично загрузить канал и не давать качать остальным. И вот тут, прежде чем что-то делать, надо уже придумать схему (политику), согласно которой различные хосты (группы хостов) смогут делить пропускную способность общего канала, а так же, как и в каком приоритете одни хосты будут "отбирать" пропускную способность у других хостов. Например, пользователи с выскоим приоритетом хотят чтобы, когда они качают "нечто важное", им отдавалась большая часть пропускной способности канала - естественно за счет "ущемления" других потребителей трафика. И даже между ними (пользователями с высоким приоритетом) желательно как-то явно поделить канал (поровну или опять же - по приоритету). Вот эту задачу (придумать политику использования канала) и надо решить перед тем как что-то делать. И это мы еще не учли влияние входящяго трафика!
После такого вводного отступления вернёмся к traffic control.
Вот для того, что бы получить нужное поведение трафика, например схожее с вышеописанным, и используют различные дисциплины очередей (qdisc) и их комбинации.
Дисциплины (qdisc) могут быть двух видов:
- безклассовые (clasless) и
- с поддержкой классов (classful, для краткости - "классовые")
Classful qdisc позволяют определить классы. К каждому из классов можно привязать:
- Другие классы, тем самым построить иерархию (дерево) классов. В каждом классе задается собственная дисциплина, совпадающая с дисциплиной родительского класса или отличная от неё. Т.о. иерархия классов фактически задаёт иерархию очередей с потенциально различными свойствами.
- Фильтры, которые будут классифицировать (фактически помечать) тот или иной вид трафика в тот или иной класс
- Безклассовую дисциплину очереди (clasless qdisc) - чтобы управлять трафиком в данном классе определенным образом
- Классовую дисциплину очереди (classful qdisc) - начав, таким образом, новую иерархию, базирующуюся на дисциплине, отличной от "корневой"!
Ниже приведен абстрактный пример со всеми четырьмя случаями:
(1) tc qdisc del dev eth0 root (2) tc qdisc add dev eth0 root handle 6: htb r2q 5 (3) tc class add dev eth0 parent 6: classid 6:1 htb rate 48Kbit ceil 48Kbit (4) tc qdisc add dev eth0 parent 6:1 handle 7: prio (5) tc qdisc add dev eth0 parent 7:1 handle 10: sfq (6) tc qdisc add dev eth0 parent 7:2 handle 20: tbf rate 20kbit buffer 1600 limit 3000 (7) tc qdisc add dev eth0 parent 7:3 handle 30: pfifo (8) tc class add dev eth0 parent 6: classid 6:2 htb rate 48Kbit ceil 48Kbit (9) tc class add dev eth0 parent 6:2 classid 6:3 htb rate 24Kbit ceil 48Kbit (10) tc class add dev eth0 parent 6:2 classid 6:4 htb rate 24Kbit ceil 48Kbit
В данном примере к egress (root) интерфейса присоединена classful HTB дисциплина (команда 2). К дисциплине присоединены два класса: 6:1 и 6:2 с гарантированной полосой 48 кбит (команды 3 и 8). Обмена токенами (свободной полосой пропускания) между этими классами не будет, так как у них нет общего родительского класса. Далее, к классу 6:1 присоединена дисциплина classful PRIO в которой (автоматически созданы) три класса: 7:1, 7:2, 7:3, к каждому из которых, в свою очередь подключены clasless дисциплины sfq, tbf, pfifo. К классу 6:2 подключены два дочерних класса 6:3, 6:4. Каждому из них гарантированы 24 кбита из 48 кбит родительского класса 6:2. И каждый из 6:3 и 6:4 может позаимствовать у другого до 48 кбит, если в каком-то из них есть свободные токены (свободная пропускная способность).
Описанные команды задают только иерархию классов, но никак не определяют каким пакетам какой класс назначить (что влмяет на время и порядок отправки пакетов из очереди в физ. интерфейс). Чтобы указать какому трафику какой класс назначить надо воспользоваться фильтрами (tc filter ...) Фильтры (filter) позволяют классифицировать трафик: каким пакетам какой из классов классовой дисциплины назначить.
Фильтры могут существовать только в классовых (classful) дисциплинах и всегда привязываются к определенному классу (без опции parent фильтр добавляется в корневой класс дисциплины, а если дисциплина безклассовая то фильтр просто не добавится - будет выдана ошибка...). Это значит что фильтры не являются глобальными сущностями - фильтр, привязанный к данному классу, используется только для классификации того трафика, которому назначен этот класс ("который попал в этот класс").
Входящий трафик и почему им невозможно управлять. Policing
Всё вышесказанное относилось только к исходящему трафику. С входящим трафиком несколько иная ситуация. Строго говоря, управлять тем, как откуда-то нам посылают пакеты (и как следствие тем, что приходит на "наш" интерфейс) принципиально невозможно. Рассмотрим почему.
Рассмотрим один единственный интерфейс, который обменивается трафиком с неким другим, удаленным интерфейсом.
Мы можем только игнорировать уже пришедшие пакеты, либо обрабатывать их дальше - мы не можем кого-то заставить слать "нам" пакеты с определенной скоростью.
В случае некоторого типа трафика возможно косвенное управление входящим трафиком, но это ничего не гарантирует. Например протокол TCP имеет механизм "управление заторами" (congestion control), который позволяют не допускать превышения пропускной способности всей цепи (сети, маршрутизаторы) между клиентом и сервером. Для этого, в частности, используется анализ прихода подтверждающих пакетов от противоположной стороны (пакеты с установленным флагом ACK). И, например, клиент, манипулируя отправкой этих пакетов (или игнорируя часть входящих), может косвенно вынудить сервер уменьшить скорость передачи - в надежде, что сервер подстроится под эти условия. Казалось бы - вот оно! Но это работает, только если сервер будет "подчиняться правилам хорошего тона" и только в случае TCP (или каких-то других протоколов с поддержкой congestion control).
Например в "голом" IP ничего такого нет, и в UDP тоже. Т.е. на исходящем интерфейсе мы можем принудить трафик к определённому поведению, а вот другую, удалённую сторону соединения мы не можем в принципе принудить - только в некторых случаях "вежливо попросить". Т.о. мы можем явно влиять на загрузку канала в направлении "от нас" и не можем в направлении "к нам".
Кто-то может возразить, что если та система, которая шлёт пакеты "в нашу строну" доступна нам для настройки, то мы можем управлять трафиком на ней. Но ведь для той системы это и будет исходящий трафик. Речь же идет о влиянии "принимающей" системы на "отправляющую".
Обратите внимание, что собственно policing может применяться как для входящего так и для исходящего трафика. Просто входящим можно управлять только с помощью policing'а, а исходящим - всеми доступными средствами: и с помощью qdisc и с помощью policer. И это может приводить к некоторым двухсмысленным ситуациям (см. Вопросы без ответов).
На примере последовательности команд рассмотрим в общих чертах, возможности policer и представим, что можно сделать с входящим трафиком.
(1) tc qdisc add dev eth1 handle ffff:0 ingress
(2) tc filter add dev eth1 parent ffff:0 protocol ip prio 1 u32 match ip dport 110 ffff \
police rate 256kbit burst 10k continue flowid 44:1
(3) tc filter add dev eth1 parent ffff:0 protocol ip prio 2 u32 match ip dport 110 ffff \
police rate 128kbit burst 5k drop flowid 44:2
В первой (1) команде мы добавляем дисциплину для входящего трафика (ingress) для интерфейса eth1. Указан handle ffff:0 так как именно ffff:0 зарезервирован для ingress.
Во второй (2) команде к ingress дисциплине прикрепляется фильтр с приоритетом равным 1 и содержащий policer. В третьей (3) команде также подключается фильтр с приоритетом равным 2 и содержащий policer. Приоритет будет определять порядок перебора фильтров, о чём ниже.
Команда (2) добавляет в ingress eth1 фильтр, ограничивающий входящий на tcp порт 110 трафик величиной 256 kbit. Трафик, укладывающийся в 256 kbit, будет классифицироваться как 44:1. Так как в policer'е 2-ой команды указано continue, то трафик превышающий 256 kbit (те пакеты, при прохождении которых уже будет превышен лимит в 256 kbit) будет подпадать под действие следующего по порядку фильтра, заданным в команде (3). Т.о. 2-ая команда фактически ничего не ограничивает, а только вычленяет из трафика "полосу" в 256 кбит и назначает ей определенный класс. Третья команда добавляет фильтр, который "подхватывает" трафик, превысивший лимит, заданный в преыдущем фильтре и вычленяет из него полосу в 128 кбит и назначает ему класс 44:2, а трафик превысивший 128 кбит он просто игнорирует (т.к. указан drop).
Т.о. оба фильтра, суммарно, ограничивают входящий трафик величиной 256+128=384 кбита. Если же, например первый же фильтр имел бы drop в policer'е, то ограничение накладывал бы только он (величиной в 256 кбит), и второй бы фильтр вообще не имел бы смысла: трафик, превышающий 256 кбит, был бы "сдропан" первым фильтром и до второго бы никогда не дошел.
Осталось разобраться что даёт возможность присваивать классы в фильтрах для ingress.
В документации tc и во всех примерах упоминается что в команде 'tc policer...' параметр flowid является обязательным. Если при использовании policer в egress виден смысл и назначение параметра flowid, каковы его функции при использовании policer в ingress (ведь это обязательный параметр) - пока загадка! Ведь в ingress не может быть классов! Например здесь в командах и описании к ним есть параметр flowid, указывающий какой класс назначить трафику, но вот что за классы подразумеваются!?
Управление трафиком в рассматриваемом примере
Рассмотрим управление трафиком в нашем примере. Имеются два подключения (не важно, к разным или к одному и тому же провайдеру). Каждое подключение это полнодуплексных (full-duplex) канал до провайдера и его пропускная способность в нисходящем (downstream) направлении (от провайдера) не зависит от загрузки канала в восходящем (upstream) направлении (к провайдеру).
Опишем, что мы хотим получить от управления трафиком. Сконфигурированная система должна позволять:
- Разделять пропускную способность каждого канала в отдельности между сетями DMZ, LAN в определенных пропорциях.
- Задавать приоритеты для различного типа трафика (SSH, RDP, DNS, HTTP, p2p и т.д.).
- Равномерно разделять пропускную способность между хостами сетей DMZ, LAN, не позволяя какому-либо из хостов этих сетей занимать канал.
- Использовать свободную пропускную способность хостами сетей DMZ, LAN в случае, если одна из этих сетей не использует выделенную ей полосу полностью.
- Задавать максимальную скорость скачивания для отдельных хостов.
Из рис. 3 видно, что для того чтобы полностью контролировать канал (например от ISP1) в нисходящем направлении, надо одновременно управлять трафиком следующих потоков:
- INET>eth1-eth0>LAN и INET>eth1-pppX>LAN,
- INET>eth1-eth2>DMZ,
- INET>eth1-GW
Объединённое управление трафиком на нескольких интерфейсах (IFB, IMQ - одна дисциплина на несколько интерфейсов)
Так как одну (и ту же) дисциплину нельзя привязать к нескольким интерфейсам, то невозможно согласованно управлять трафиком на нескольких интерфейсах. Ниже показаны как раз такие ситуации для рассматриваемой нами схемы. На первой схеме показана ситуация, когда весь трафик во внутренние сети (LAN и DMZ) поступает через провайдера ISP1. Второй рисунок иллюстрирует ситуацию, когда трафик в LAN поступает через ISP2, а трафик в DMZ - через ISP1.
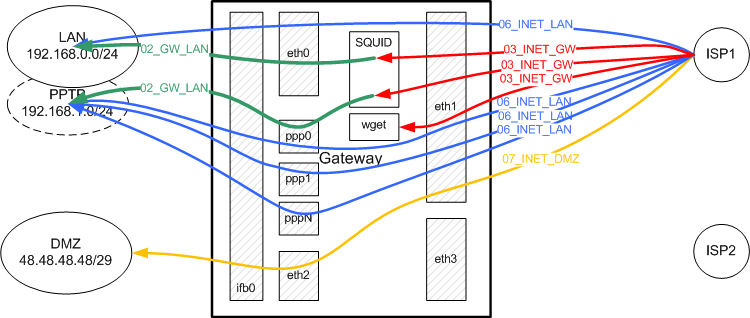
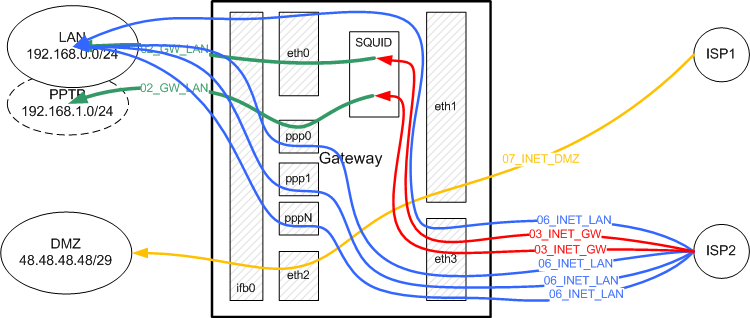
В первом случае видно, что загрузка канала к провайдеру ISP1 зависит от суммарного потребления трафика клиентами в сети LAN, pptp-клиентами в сети LAN и серверами сети DMZ. Таким образом, если, например, pptp-клиент подключенный, через (виртуальный) интерфейс ppp1 начнет качать, со скоростью равной пропускной способности канала до ISP1, то другим хостам "ничего не достанется". Можно, например, задать каждому ppp-интерфейсу свою индивидуальную дисциплину с нужными ограничениями, однако это не решит проблему эффективного распределения свободной пропускной способности канала. Сказанное относится и к интерфейсам eth0, eth1, eth2 через которые внутренние сети получают трафик.
В рамках одного экземпляра ОС задача решается использованием некоего специального виртуального устройства (интерфейса), у которого есть очередь пакетов и к которому можно прикрепить дисциплину. Также нужен механизм, перенаправляющий (внутри ядра) трафик с желаемых интерфейсов на этот виртуальный интерфейс. Таким образом достигается некая "агрегация" желаемого трафика на одном интерфейсе, где им бы можно было управлять в рамках одной дисциплины очереди. Добиться подобного мрашрутизацией (видимо?) нельзя, так как перенаправление дожно происходить уже после (для исходящего трафика) или до (для входящего) этапов маршрутизации.
На данный момент для ядра Linux cуществуют два таких уcтройства:
- IMQ (Intermediate Queueing Device) и
- IFB (Intermediate Functional Block).
IFB-интерфейс - узкоспециализированное устройство и оно не является полноценным сетевым интерфейсом, как например виртуальные ppp или tun. Интерфейсы IFB не могут иметь IP-адрес, они не "видны" как устройства в iptables, но на них можно перехватывать трафик с помощью tcpdump. Исходящим интерфейсом всегда будет тот, с которого трафик перенаправлен на IFB, а не сам IFB-интерфейс.
Итак, на схемах показан IFB-интерфейс ifb0, условно "объединяющий" трафик с разных интерфейсов, что и даёт возможность управлять им как единым целым в рамках одной дисциплины, прикрепленной к ifb0.
После этого отступления переходим непосредственно к рассмотрению конфигурирования управления трафиком в нисходящем канале.
Управление трафиком в downstream-канале
С учетом вышеизложенного конфигурирование будет состоять из следующих шагов:
- обьединение трафика на виртуальном IFB-интерфейсе для создания единой дисциплины управления трафиком потоков, загружающих downstream-канал;
- настройка дисциплины IFB-интерфейса (в т.ч. создание иерархии классов)
- классификация трафика при помощи NETFILTER (iptables target CLASSIFY)
Обьединение трафика на виртуальном IFB-интерфейсе
Рассмотрим команды, необходимые для конфигурирования IFB-интерфейса и перенаправления на него трафика.
Сначала надо загрузить модуль ядра и если необходимо более двух IFB-устройств, указать в параметрах модуля необходимое их кол-во, например четыре.
modprobe ifb numifbs=4
Затем активируем интерфейсы, как и обычные:
ifconfig ifb0 up ifconfig ifb1 up ifconfig ifb2 up ifconfig ifb3 up
А далее надо перенаправить трафик с нужных нам интерфейсов на один из IFB-интерфейсов. В нашем примере для управления нисходящим трафиком будем использовать ifb0.
Перенаправляем трафик c eth0 (LAN) на ifb0.
(1) tc qdisc del dev eth0 root (2) tc qdisc del dev eth0 ingress (3) tc qdisc add dev eth0 root handle 1: prio (4) tc filter add dev eth0 parent 1: protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0Первые две команды удаляют прикрепленные (если они были) дисциплины у egress (1) и ingress (2). Далее, к egress прикрепляем какую-нибудь, обязательно классовую дисциплину (3), например самую "простую" - PRIO.
И командой (4) производится собственно перенаправление - используются так называемые actions.
Перенаправляем трафик c eth2 (DMZ) и на ifb0.
(1) tc qdisc del dev eth2 root (2) tc qdisc del dev eth2 ingress (3) tc qdisc add dev eth2 root handle 1: prio (4) tc filter add dev eth2 parent 1: protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0
Для ethernet-интерфейсов эти команды можно выполнить один раз, в момент инициализации интерфейса.
В случае ppp-интерфейсов ситуация осложняется тем, что они создаются и уничтожаются динамически. Поэтому схожую последовательность команд, надо выполнять при создании каждого ppp-интерфейса, в скрипте, выполняющемся при активации ppp-интерфейса. В Debian это будет некий скрипт, расположенный в специальном каталоге /etc/ppp/ip-up.d/. Пусть в нашем случае этот скрипт называется tc-ppp.
/etc/ppp/ip-up.d/tc-ppp: tc qdisc del dev $PPP_IFACE root tc qdisc del dev $PPP_IFACE ingress tc qdisc add dev $PPP_IFACE root handle 1: prio tc filter add dev $PPP_IFACE parent 1: protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0где в переменной PPP_IFACE будет имя активированного интерфейса. Значение переменной PPP_IFACE будет передано демоном pppd через скрипт /etc/ppp/ip-up.
Таким образом, при подключении каждого pptp-клиента, автоматически будет выполняться этот скрипт и исходящий трафик с ppp-интерфейса этого клиента будет перенаправлен на ifb0.
Теперь весь трафик (кроме входящего на eth1, который пока опускаем для простоты!) "собран" на ifb0 и всё должно работать как и ранее, до перенаправления. Далее рассмотрим схему классов для HTB-дисциплины, которую мы будем использовать для управления трафиком на ifb0.
Настройка дисциплины IFB-интерфейса и создание иерархии классов
Сначала рассмотрим схему классов для управления трафиком только в одном из каналов - к ISP2.
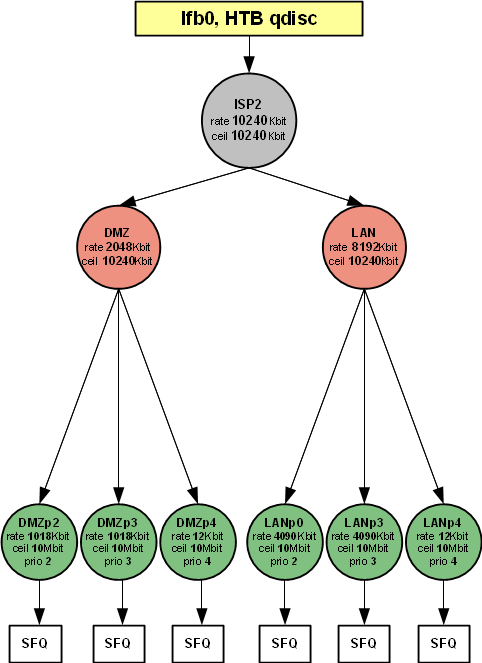
К ifb0 прикрепляем HTB дисциплину и создаем "корневой" класс, чтобы все подчиненные классы могли занимать (borrow) друг у друга свободную пропускную способность (п.4 списка). У данного класса rate и ceil равны пропускной способности канала в нисходящем направлении - 10 Мбит/с (10240 Кбит/с).
К "корневому" классу прикрепляем два подчиненных класса, обозначенные на схеме как LAN и DMZ. Эти два класса служат для задания пропорции, в которой сети LAN и DMZ будут делить пропускную способность канала (п.1 списка). В моменты, когда одна из этих двух сетей не использует канал, другая сеть может загрузить канал полностью. В моменты же, когда хосты обеих сетей одновременно стремятся максимально загрузить канала, каждой сети будет выделяться только часть пропускной способности, согласно заданной пропорции. Т.о. и в моменты максимальной загрузки ни одна из сетей не сможет полностью захватить канал, ничего не оставляя другой сети.
Для обеспечения приоритетов (п.2 списка) различных типов трафика, у классов LAN и DMZ создаем по три подчиненных класса (на схеме - LANp2, LANp3, LANp4, DMZp2, DMZp3, DMZp4) с различным значениями приоритета и rate/ceil. Приоритезация трафика полезна вот для чего. например, если в сети LAN хосты начнут загружать канал второстепенным трафиком, не столь важным для рабочих целей, то прохождение более важного трафика замедлится, начнут расти задержки и падать его скорость. Классический пример трафика, который часто "мешает" в офисной сети - p2p-трафик (LANp2), а к самым приоритетным типам трафика можно отнести SSH, RDP, DNS, ACK-пакеты, VoIP (LANp2). HTTP и FTP трафик можно в этом случае отнести к классу LANp3. Кроме приоритета, каждому из трех классов назначается свои значения rate/ceil, аналогично тому, как это сделано для классов LAN и DMZ. Это позволит задать некий гарантированный для каждого типа трафика минимум (rate) и максимум (ceil) скорости.
Т.о. благодаря приоритезации, даже если в сети будут хосты, стремящиеся занять весь канал p2p-трафиком, более важный трафик (SSH, RDP и т.д.) будет пропускаться первым, а менее важный трафик в этот момент не привысит заданную минимальную скорость и не будет мешать более важному, так как часть второстепенного трафика, привысившая заданный порог уже будет вынуждена ожидать, пока канал не будет освобожден более приоритетным трафиком.
Ну и, наконец, так как в каждый из классов у нас будет классифицироваться трафик от нескольких хостов, а не от одного будет полезно как-то их "уровнять в правах" между собой, в рамках каждого из типов трафика (п.3 списка). Для этого к каждому классов с приоритетом подключеам дисциплину SFQ, которая более-менее равномерно и справедливо "раздает" в каждом из классов пропусную способность хостам.
Т.о. данной иерархией классов мы добились решения всех задач, поставленных в начале, кроме последней - "задавать максимальную скорость скачивания для части хостов сетей LAN и DMZ". Переходим к решению данной задачи.
Для задания индивидуальных скоростных ограничений необходимо для каждого ограничиваемого хоста добавить группу классов с минимально возможным значением rate, и ceil, равным величине требуемого ограничения. На схеме ниже показана схема классов, реализующая ограничение скорости скачивания для двух хостов из сети LAN: host1 и host2.
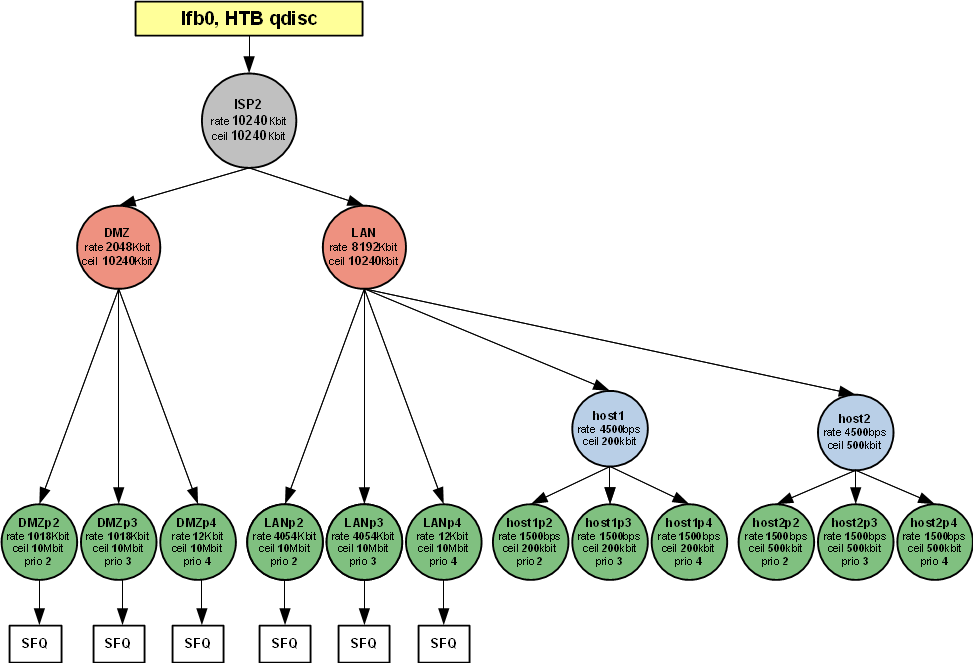
Собственно классы host1 и host2 необходимы для возможности задать индивидуальное ограничение для хостов (ceil 200Kbit и ceil 500Kbit сооответственно). Так как в HTB-классе параметр rate является необходимым (т.е. rate не может быть равен 0), то каждому хосту, которому мы захотим задать индивидуальные настройки, придется дать некий гарантированный минимум, который бессмысленно делать меньше MTU (1500 байт для стандартного Ethernet). В нашей схеме это 4500bps (три класса по 1500bps). Заметьте, что пока узел не был выделен в отдельный класс, ему (и другим) по сути никакого минимума не гарантировалось. Выделяя же узел в отдельный класс приходится дать гарантированый минимум, отбирая тем самым часть rate у подчиненных классов класса LAN: у LANp2 отобрали 32Kbit (4500 байт/с * 8) и у LANp3 тоже 32Kbit. Т.е. на каждый узел, которому мы захотим дать индивидуальные настройки, придется отдать как минимум гарантированные 32Kbit (3*8*1500 байт/с).
Посмотрим зачем нужны подчиненные классы приоритетов для классов host1 и host2. Если бы подчиненных классов не было и приоритеты были бы указаны прямо у классов host1 и host2, то тем самым была бы нарушена логика работы данной иерархии классов. Т.е. весь трафик для такого хоста подпадал бы под один заданный класс и приоретизровался не так, как трафик других хостов. Например, если бы классу host1 дали prio 2, то его трафик стал бы приоритетнее трафика всех остальных хостов, а если бы prio 4 - то наборот. Это как раз то что треубется, если наша задача - дать преимущество какому-нибудь хосту. Мы же хотим всего лишь задать верхнюю границу скорости скачивания для выбранного хоста и чтобы при этом правила приоритезации оставались едиными и неизменными для всех хостов сети LAN.
Поэтому необходимо к классу host1 (и к каждому классу, играющему роль ограничителя) прикрепить иерархию классов с приоритетами, аналогичную той, что используется и для всех остальных, но естественно со своими собственными значениями rate и ceil. Так как к классам host1p2/3/4 будет относится трафик только одного хоста, а не нескольких как у классов LANp2, LANp3, LANp4, то нет необходимости присоединять к ним дсициплину SFQ. Естественно, всё вышесказанное справедливо и для сети DMZ, для хостов которой, по тому же принципу, можно задвать индивидуальные настройки.
Приведенная схема классов позволяет реализовать все указанные выше требования, а также в общем задавать индивидульные настройки для отдельных хостов. Например, устанавливая определенную величину rate можно выделить гарантированную полосу пропускания, а устанавливая меньшие/большие приоритеты, можно давать преимущество на скачивание одним хостам по отношению ко всем остальным. Например, если необхоидмо дать преимущество хосту host1, по отношению ко всем остальным хостам, то достаточно установить у класса host1 prio 2, а подчиненные классы не создавать вовсе, так как они в этом случае становятся излишними, и трафик к хосту host1 будет обслуживаться наравне с трафиком класса LANp2. Если, например необходимо дать классу host1 абсолютное преимущество, то можно установить величину его prio меньше, чем у любого из классов, например prio 1.
Недостаток у данной схемы следующий: с ростом кол-ва хостов, которым необходимо задать индивидуальные настройки быстро растёт и общее количество классов и иерархия классов становится очень громоздкой. Например, в показаном на схеме варианте с делением трафика на три типа (с тремя приоритетами), каждый узел с индивидуальными настройками требует создания четырех классов (класс для хоста + три подчиненных). Если мы захотим более детально делить трафик на типы, например на пять типов, то это уже даст по шесть классов на каждый узел с индивидуальными настройками. Мне неизвестно какова реальная масштабируемость подсистемы traffic control по кол-ву классов и как большое кол-во классов сказывается на производительности. Кроме того каждому такому хосту необходимо выделить некий минимум пропускной способности, кратный MTU помноженному на количество подчиненных классов для типов трафика, что тоже ограничивает разумное кол-во таких хостов. Из конечной ширины канала можно получить конечное число полос с гарантированной полосой. В нашем примере для сети LAN (8192 Кбит/с) можно "нарезать" 256 полос по 32 Кбит, а ведь еще надо что-то оставить для остальных.
В случае, если в рассмотренном выше примере, необходима лишь возможность ограничивать скорость скачивания, а возможности приоритезации и гарантированной полосы пропускания для отдельных хостов не нужны, то можно сконфигурировать две независимые друг от друга HTB-дисциплины на двух разных интерфейсах, как схематично показано ниже.
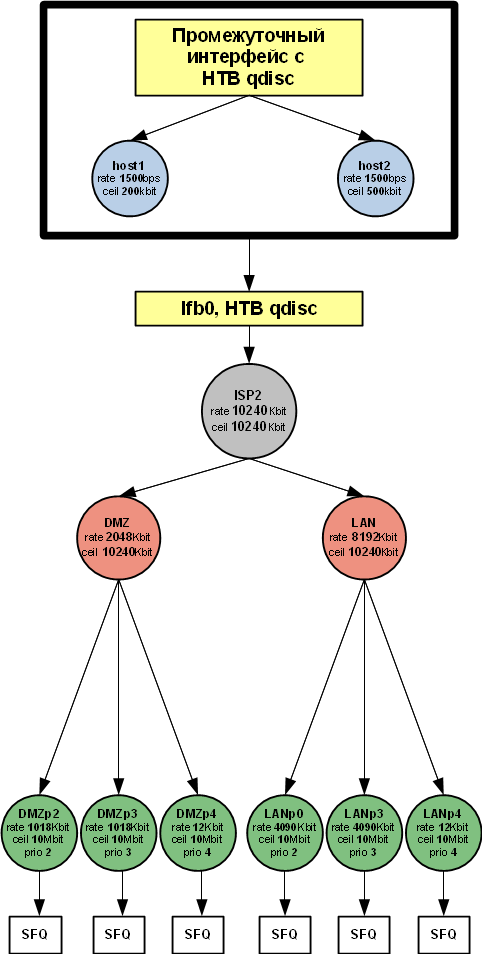
С помощью HTB-дисцплины на промежуточном интерфейсе происходит ограничение максимальной скорости скачивания для выбранных хостов, а на следующем интерфейсе, куда трафик попадает с промежуточного, уже независимо происходит приоритезация и разделение пропускной способности по сетям и типам трафика. Т.е. получаем некую двухступенчатую схему управления трафиком в нисходящем канале. Но для этого нужны два исходящих интерфейса через которые проходил бы трафик.
К сожалению, выстроить цепочку из IFB-интерфейсов не получится. Т.е. перенаправить
трафик с ethX или pppX на IFB можно, а вот далее с этого IFB на другой IFB-интерфейс - нельзя.
Из файла doc\actions\mirred-usage в исходниках iproute2:
"Do not redirect from one IFB device to another...
Redirecting from ifbX->ifbY will actually not crash your machine but your
packets will all be dropped"
Проверено - всё именно так.
Поэтому нужнен "нормальный" промежуточный интерфейс, а не IFB.
И решить эту задачу в одном экземпляре ОС с помощью, например TUN тоже не получится,
ибо нам необходимо, чтобы в конце концов трафик "уходил" со своего "родного" интерфейса:
в случае (eth0,eth2) -mirred redirect-> ifb0 это работает, так как на самом деле IFB просто
помещает пакет в то же место сетевого стека, откуда он был "подобран".
Очевидно в цепочке (eth0,eth2) -mirred redirect-> tunX -mirred redirect-> ifb0
это работать не будет.
Возможность использования TUN как некоего абстрактного интерфеса, на который можно
перенаправить (mirred action) траффик с eth0, eth2 и eth1, потом с этого tun
перенаправить трафик на ifb0 не изучен на практике - проверить. (Проверил - не работает).
Т.о. образом приходим к выводу, что для реализации этого подхода надо использовать либо две физические/виртуальные машины, либо контейнеры. И всё это чтобы сократить общее кол-во классов в дисциплинах очереди. Вообще пока первоначальный вариант остается самым универсальным.
Иерархия классов для двух каналов/провайдеров
Описанная выше схема классов подходит для случая, когда весь входящий трафик поступает через одно подключение - именно загрузкой этого канала мы и управляем. При наличии двух каналов с разными публичными IP (к одному или разным провайдерам) расмотренной выше схемы управления трафиком становится недостаточно в силу того, что она задает правила только для одного из каналов, в то время как второй остается без управления. В случае одновременного использования двух подключений, трафик даже к одному и тому же хосту в сети, например LAN, может одновременно поступать через два канала за счет применения policy routing. И даже если два подключения не используются одновременно, то при переключении на другой канал (предположим именно он не сконфигурирован), возникнет ситуация неуправляемой загрузки этого канала, особенно если его пропускная способность меньше основного. Люди же привыкают к "толстому" каналу, загружают его "по полной" и при переключении менее "толстый" канал "ложится". Поэтому, чтобы управлять загрузкой двух каналов в нисходящем направлении необходимо на интерфейсе ifb0 сконфигурировать две иерархии - каждая со своими характеристиками, подходящими для пропускной способности "своего" канала. Естественно это повлияет и на классификацию трафика. В случае использования двух каналов уже будет нельзя использовать один набор правил классификации для всего трафика из Интернета, как это делалось в случае одного канала. Трафик из сети Интернет в сеть LAN (а равно и DMZ) необходимо будет классифицировать по разному, в зависимости от того через какой канал (интерфейс eth1 или eth3) он пришёл. Для такой классификации в таблице mangle для трафика Internet -> LAN/DMZ будет использоватья две цепочки, а не одна.
Посмотрим на схему классов для двух каналов с пропускной способностью в downstream 10 Мбит/с и 512 Кбит/с.
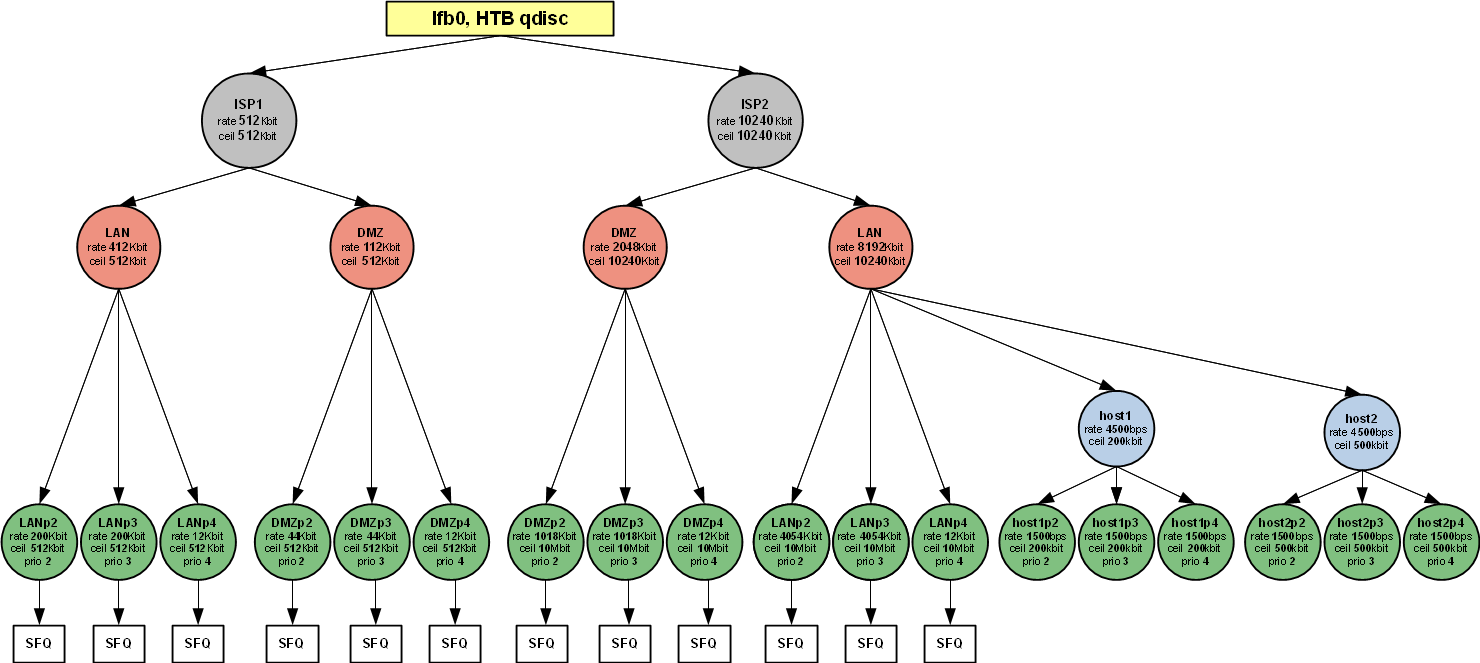
К описанной ранее иерархии классов (правая часть диаграммы) в корень HTB-дисциплины добавлен второй класс ISP1 с rate и ceil равными пропускной способности другого канала. Классы ISP1 и ISP2 не имеют общего родительского класса и прикреплены напрямую к HTB-дисциплине, поэтому не могут обмениваться между собой свободной пропускной способностью. Именно это и требуется, так как у нас два независимых канала, пропусная способность которых просто физически не может быть "передаваться" от одного другому.
К классу ISP1 прикреплена иерархия классов аналогичная иерархии классов в ISP2, только с величинами rate/ceil уменьшенными пропорционально меньшей пропускной способности второго канала. Т.о. иерархия класса ISP1 будет регламентировать загрузку канала до провайдера ISP1, а класса ISP2 - до провайдера ISP2. При этом в иерархии классов ISP1 индивидуальные настройки тоже реализуются созданием отдельных подклассов для отдельных хостов, аналогично тому, как это было показано для класса ISP2.
Классификация трафика при помощи NETFILTER
Для классификации трафика можно воспользоваться возможностями tc filter classifier, а можно использовать возможностями NETFILTER. Для классификакции трафика в NETFILTER есть target CLASSIFY, с помощью которой можно проставлять пакету класс, заданный в подсистеме traffic control (классифицировать пакет). Классификация возможна только в таблице mangle NETFILTER.
В рассматриваемой конфигурации используется классификация с помощью NETFILTER, так как для меня проще отбирать нужные пакеты с помощью NETFILTER, чем возиться с классификаторами tc filter. В таблице mangle у меня уже формируются цепочки по потокам - остается только вставить нужное правило классификации в нужную цепочку. Возможно классификация при помощи tc filter быстрее, особенно для большого числа правил (см. tc hashing filters). Пока не ясно как в классификаторе tc filter отбирать указывать условия эквивалентные возможностям ipset.
Классификация возможна только в таблице mangle. Правила в таблице mangle организуем по тому же принципу, что и в таблице filter: каждому потоку свою цепочку с правилами плюс переходы на них со встроенных цепочек согласно адресам сетей. Рассмотрим листинг команды iptables -nvL -t mangle: нас интересуют цепочки 06_INET_LAN и 07_INET_DMZ.
В цепочке 06_INET_LAN мы классифицируем трафик для всех четырех хостов (boss, admin, user, server) в сети LAN. Правила (выделены синим) для перехода в цепочку 06_INET_LAN находятся во встроенной цепочке FORWARD.
Правила для классификации трафика для хостов в сети DMZ расположены в цепочке 07_INET_DMZ. Правила (выделены желтым) для переходов в цепочки 07_INET_DMZ расположены во встроенной цепочке FORWARD.
Управление трафиком и SQUID
Как видно из рис. 10 и 11 хосты сетей LAN и DMZ могут использовать канал до провайдера не только напрямую, но и опосредованно - через прокси-сервера, если таковые работают на шлюзе. В рассматриваемом примере это SQUID - http/ftp прокси.
Исходящий трафик от хоста сети LAN к какому-либо http-серверу может быть явно направлен через прокси, либо принудительно перенаправлен на локальный прокси средствами NETFILTER (transparent proxy, "прозрачный прокси"). В результате узел сети LAN уже не устанавливает прямое соединение с целевым сервером: сначала трафик идет на прокси-сервер, а уже прокси-сервер создает новое соединение с целевым сервером и шлёт пакеты "от своего имени". В обратном направлении происходит тоже самое: целевой сервер отвечает прокси-серверу, а прокси-сервер передает данные клиенту. Дополнительная сложность возникает из-за того, что прокси-сервер может отдать данные клиенту взяв их из кэша и при этом канал до провайдера не будет занят передачей этих данных.
Это осложняет задачу управления трафиком, так как трафик, проходящий через прокси не является "непрерывным": он разбит на два этапа. При этом потребителем трафика http-сервер -> прокси, как видно из рис. 10 и 11, является сам шлюз, а не конечный клиент.
Поэтому, строго говоря, для такого трафика исчезает возможность управлять им на исходящих (eth0, pppN, ifb0) интерфейсах, а управление входящим трафиком (до SQUID'а, на eth1) малореалистично: надо анализировать пакеты на уровнях выше транспортного, так как "где чей пакет" уже невозможно понять на транспортном уровне (по IP источника - источник один - локальный процесс squid'a) а также "увязывать" входящую дисциплину для eth1 и исходящих (eth0, pppN, ifb0) интерфесов.
Есть два пути решения задачи управления трафиком при наличии прокси на шлюзе:
- использовать встроенные (если они есть, конечно) в прокси возможности управления трафиком
- попытаться косвенно повлиять на использование канала прокси-сервером, управляя трафиком на том интерфейсе, через который прокси отдает трафик внутренним хостам
Вариант №1: использовать возможности SQUID (версии 2.x) по управлению трафиком
Первый вариант - воспользоваться возможностями самого SQUID'а по управлению трафиком - delay pools ("пулы задержек").
Минусы:
- Единое управление загрузкой канала, как таковое невозможно: клиенты могут получать одновременно трафик как напрямую так и через squid: первым мы управляем через подсистему ядра ОС, другим - через настройки squid и они никак не связаны между собой и нет возможности из увязать. Например, если хосту выделена полоса с помощью tc, то это никак не влияет на squid и трафик получаемый хостом через squid никак не будет ограничен. Если в этом случае задать некие ограничения в настройке самого squid'а, то в лучшем случае мы ограничим узел только раздельно по этим двум путям получения трафика: невозможно будет задать единое суммарное ограничение, которое бы перераспределялось бы между трафиком через squid и другим трафиком. К тому же возможности squid в этом плане не обладают гибкостью traffic control ядра. Фактически можно лишь задать максимальную скорость для каждого хоста: невозможно из выделенной каждому пропускной способности, свободную перераспределять между другими, как это возможно в tc ядра. Например мы хоти ограничит download некоего хоста общей величиной 100 кбит/с. Для этого придется задать некую величину для tc и некую для squid. Зададим в squid - 50 кбит/c (для http трафика), и c помощью tc - 50 кбит/с (для всего остального трафика). Получим следующую проблему: пользователь этого хоста сможет получить максимальную скорость скачивания по http (например в браузере) 50 кбит/c, а не 100 кбит/c как все хотели бы. Т.е. выделенные хосту через tc другие 50 кбит/c могут быть использованы только трафиком, идущим не через squid! Та же проблема вознивает и при динамическом перераспределении пропускной способности между разными хостами (пользователями). Если канал свободен (пользователи "мало качают"), и есть некто, кому надо использовать канал для быстрого скачиваниия, то он не сможет "занять" у других неиспользуемую ими пропускную способность, как это можно сделать в tc. Это сильно ограничивает гибкость и возможности всей системы в целом. Если же мы и в squid выделим - 100 кбит/c, и c помощью tc - 100 кбит/с, то пользователь "получит свои 100 кбит/c", однако на самом деле он сможет загрузить канал на все 200 кбит/с, качая одновроеменно через squid и по другим протоколам, что уже не устраивает нас, так как нам надо "уложить" всех потребителей в пропускную способность канала.
- Усложняется администрирование: задавать ограничения надо в двух различных системах, что на практике приводит к различным несоответствиям (в tc задал, в squid забыл; в tc изменил, в squid забыл и т.п.). Ухудшается восприятие всей системы управления трафиком в целом.
-
Возможности управления трафиком в SQUID беднее в сравнении с возможностями tc и
исопльзовать их (в случае индивидуальных настроек) неудобно.
В SQUID (2.x) есть три класса (а проще говоря типа) delay pools (пулов задержки или проще буферов).
Класс 1 позволяет задать индивидульное ограничение каждому ACL SQUID'a. Этот тип можно
использовать так: создать кол-во пулов, равное количеству ограничиваемых по скорости
клиентов и затем присвоить каждому клиенту свой ACL, а каждому ACL'у - свой пул
с индивидуальным ограничением скорости. Т.е. в настройке SQUID надо писать кучу ACL'ов,
кучу пулов, задать общее количество пулов и следить за их использованием при
удалении/добавлении новых пользователей. Естественно, в этом варианте, нуждающиеся клиенты не смогут
занять у других, неиспользуемые ими ресурсы полосы пропускания.
Класс 2 позволяет задать одно, общее ограничение и задать в рамках этого ограничения ограничение для каждого из хостов, но не произвольно, а только по фиксированным битам ipv4-адреса (сеть класса C). Т.е. есть хосты будут выделяться по битам с 25 по 32, а задать индивидуальное ограничение можно только одинаковое для всех! В этом варианте, нуждающиеся клиенты тоже не смогут занять у других, неиспользуемые ими ресурсы полосы пропускания, так как индивидульное ограничение жёсткое и единое для всех. Пример:
delay_pools 1 # общее кол-во пулов - один acl server1 src 192.168.1.1 # ACL для компьютера с адресом 192.168.1.1 acl server1 src 192.168.1.2 # ACL для компьютера с адресом 192.168.1.2 acl client1 src 192.168.0.1 # ACL для компьютера с адресом 192.168.0.1 acl client1 src 192.168.0.2 # ACL для компьютера с адресом 192.168.0.2 delay_class 1 2 # пул №1 (а он у нас всего один) имеет класс 2 delay_parameters 1 40960/20480 10240/10240 # параметры пула №1 delay_access 1 allow server1 # этот у нас будет использовать пул №1 delay_access 1 allow server2 # и этот у нас будет использовать пул №1 delay_access 1 allow client1 # и этот у нас будет использовать пул №1 delay_access 1 allow client2 # и этот у нас будет использовать пул №1
Это значит, что четыре хоста (server1, server2, client1, client2) могут потреблять суммарно не более 40 кбайт\с, а каждый из них - не более 10 кбайт\с. Цифры 40960/40960 - по сути означают: первая цифра - максимальная скорость, с какой будет идти передача, после того как будет скачано кол-во байт указанное во второй цифре. Т.е. можно "сжечь" (получить без ограничения скорости) 20 кбайт данных, а после этого вступит в силу ограничение скорости в 40 кбайт\с.Класс 3 похож на 2-ой, но добавляет еще одно суммарное ограничение - по подсетям.
В SQUID 3.x появились пулы классов 4 и 5, но они также ничего нового в суть управления трафиком не вносят.
Плюсы:
- Плюс всего один: пользователи получат трафик из кэша SQUID'а на максимальной скорости. Так и должно быть, так как то, что squid взял из кэша уже не качается и не занимает канал.
Итак основными недостатками управления тарфиком в SQUID с помощью delay_pools являются: отсутствие интеграции с подсистемой управления трафиком ядра (traffic control) и как следствие - невозможность гибкого распределения неиспользуемой пропускной способности между нуждающимися в ней хостами, невозможность управления трафиком рамках единой системы и связанная с этим громоздкость конфигурирования и администрирования.
Вариант №2: косвенное влияние на использование канала SQUID'ом плюс частичная "интеграция" с traffic control
В этом варианте с помощью tc ограничивается скорость, с которой SQUID отдает трафик хостам внутренних сетей (зелёные стрелки на рис. 10 и 11). Это косвенно влияет на то, с какой скоростью squid загружает себе данные для каждого клиента.
Для этого трафик от SQUID в сЕти LAN и PPTP (цепочка 02_GW_LAN) надо проклассифицировать с помощью iptables (-j CLASSIFY) аналогично цепочке 06_INET_LAN (таблица mangle). И, естественно, этот трафик должен быть пернаправлен на интерфейс ifb0, что мы уже рассмотрели ранее. Т.о. трафик от SQUID будет проклассифицирован так же как и трафик, идущий к пользователям напрямую, "мимо" SQUID'а, и управление этим трафиком будет происходить согласно правилам для "прямого" трафика. Т.е. для целей управления трафиком, трафик идущий от SQUID во внутренние сети, так же, как интерпретируется как прямой трафик из Интернета.
Чтобы проклассифицировать трафик, идущий от SQUID во внутренние сети, надо вычленить этот трафик, из общего трафика между шлюзом и внутренними сетями.
Трафик от SQUID во внутренние сети пометим (CONNMARK) в цепочке 01_LAN_GW_ALLOW таблицы filter:
CONNMARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3128 state NEW CONNMARK xset 0x3128/0xffffffff CONNMARK tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:3129 state NEW CONNMARK xset 0x3128/0xffffffff
Далее, помеченный трафик из цепочки OUTPUT таблицы mangle отправим на классификацию в цепочку 06_INET_LAN таблицы же mangle:
06_INET_LAN all -- * eth0 0.0.0.0/0 192.168.0.0/24 connmark match 0x3128 06_INET_LAN all -- * ppp+ 0.0.0.0/0 192.168.1.0/24 connmark match 0x3128Как результат: пакеты от SQUID к внутренним хостам будут проклассифицированы также, как и пакеты приходящим им напрямую из Интернета.
Таким образом мы получаем возможность (косвенно) управлять трафиком, который идет пользователям через SQUID, средствами traffic control.
Однако, при этом, возникает следующий минус: контент, который SQUID возьмет из своего кэша, будет отдаваться не на максимально возможной скорости, а с ограничением, установленным для данного клиентского хоста. Это происходит потому, что подсистема traffic control, естественно, не может "понять" откуда SQUID получил передаваемый контент - из своего кэша или из Интернета.
От этого недостатка можно избавиться следующим образом. Начиная с версии SQUID 2.7 появилась возможность пометить трафик, который squid берет из кэша. Для "отметки" можно использовать поле TOS заголовка IPv4 пакета.
Ниже показаны две дерективы, которые надо использовать в конфигурационном файле SQUID 2.7:
zph_mode tos zph_local 0x88Первая (zph_mode tos) включает пометку пакетов в зависимости от попадания/промаха (HIT/MISS) в кэше SQUID.
Вторая (zph_local 0x88) - задает (произвольное) значение поля TOS IP-пакета для контента взятого из локального кэша SQUID'а.
С этими директивами, IP - пакеты контента, взятого из кэша (HIT), будут иметь поле TOS равное 0x88, а пакеты контента взятого не из кэша (MISS) - 0x00.
На данный момент предыдущие варианты использования поля TOS аннулированы (RFC 3168, section22) и сейчас биты 0-5 это DSCP, а 6-ой и 7-ой - ECN (RFC 3168, page 8), то число, которое вы выбираете для zph_local, в двоичной форме должно иметь нули в 6-ом и 7-ом битах. Например: 0x88 - 10001000 (136 дес.), 0x58 - 01011000 (88 дес.), 0x20 - 00100000 (32 дес.).
http://bytesolutions.com/Support/Knowledgebase/KB_Viewer/ArticleId/34/DSCP-TOS-CoS-Presidence-conversion-chart.aspxВ SQUID 3.1 принцип тот же, но директива называется по другому (qos_flows) и имеет другой синтаксис: (http://wiki.squid-cache.org/Features/QualityOfService)
Как результат - исчезают все минусы, указанные в Варианте №1: появляется возможность целостного управления входящим трафиком из сети Интернет во внутренние сети, упрощается админстрирование, так как не надо управлять скоростями в двух разных системах (ядре и SQUID).Roadwarriors: мобильные клиенты. Доступ к внутренним сетям и VPN.
Со временем у сотрудников появляется необходимость получить доступ к ресурсам внутренних сетей извне. Например, сотруднику надо из Интернета (дом, командировка) подключиться удаленным рабочим столом к своему компьютер, стоящему в офисе и что-то на нём посмотреть или поработать с него с какими-либо проложениями. Фактически, это позволяет находясь вне офиса, работать за своим офисным компьютером почти также как если бы сотрудник лично сидел за ним в офисе: получать тот же доступ к внутренним ресурсам и т.п. Таким же образом можно организовать прямой доступ к серверам и приложениям, работающим на хостах внутри офисной сети, не выставляя их в публичный доступ. Или, например, маршрутизировать трафик от удаленного работника через офисный шлюз, создавая для ресурсов Интернета иллюзию того, что трафик идет непосредственно из офиса. Это полезно, если нужные сотруднику ресурсы разрешают доступ только с адресов офисного шлюза.
"Напрямую" такое сделать невозможно: и из-за фаервола и из-за частных адресов, используемых во внутренних сетях. Непосредственно можно подключиться только хостам, имеющим публичные IP-адреса (например сам шлюз и сеть DMZ) и только если к ним разрешён доступ в фаерволе.
Для того, чтобы организовать такой "прямой" и что важно защищённый доступ к хостам внутренней сети извне можно использовать VPN. По сути VPN создаёт туннель, виртуальное соединение, между компьютером мобильного клиента и шлюзом, инкапсулируя полезный трафик "внутри" "несущего" трафика между ними. Кроме того, обычно, VPN можно настроить так, что для создания этого туннеля (т.е. для подключения к VPN серверу) мобильный клиент должен пройти процедуру аутентификации. Т.о. только лица, знающие аутентификационные данные смогут подключиться к VPN серверу и получить доступ к внутренним сетям.
Естественно, реализация такой возможности, потенциально открывает для посторонних ещё одну возможность получить доступ к внутренней сети. В случае утечки аутентификационных данных (ключей, паролей) легитимных пользователей, посторонний сможет подключиться к VPN-серверу и получить доступ ко всему, к чему имеет доступ реальный пользователь. Из-за неправильного конфигурирования VPN-сервера или наличия уязвимостей в сервере/клиенте/протоколе VPN, возможны неавторизованные подключение, взлом сервера VPN или шлюза или всей сети в целом.
В любом случае, рекомендуется очень чётко ограничить, к каким внутренний ресурсам получает доступ пользователь через VPN. Однако, например, если сотруднику разрешено подключиться через VPN удалённым рабочим столом (получить шелл) к компьютеру внутри сети, то уже его мало что сможет ограничить в его действиях. Поэтому желательно сегментировать внутреннюю сеть, изолируя различные её части друг от друга, тем самым ограничивая часть сети, на которую сможе воздействовать злоумышленник, получивший такой доступ.
Функционирование VPN с точки зрения фаервола
Как уже говорилось выше, VPN всего лишь создает туннель между VPN-сервером и мобильным клиентом. Поэтому всех подключенных клиентов VPN (или их часть) можно рассматривать как просто еще одну IP-сеть, подключенную к шлюзу через (виртуальный) интерфейс. С точки зрения маршрутизации и фаервола это такая же сеть, как и например LAN, DMZ. Опять, же таких VPN сетей можно организовать несколько, выделив каждой группе пользователей по отдельной IP-сети.
В зависимости от конкретной реализации, сервер VPN либо может создавать виртуальный интерфейс, являющиеся серверным концом этого туннеля, либо работать без создания виртуальных интерфейсов. В случае, если используемый сервер VPN создает для своей работы виртуальные интерфейсы (напр. OpenVPN, PPTP), эти интерфейсы будут входящими/исходящими в iptables для туннелируемых пакетов (payload protocol).
Если используемый сервер VPN не создает виртуальные интерфейсы в своей работе (напр. IPSec/NETKEY), то в цепочках iptables будут "видны" уже распакованные из туннеля и заново инжектированные в сетевой стек пакеты VPN-протокола (payload protocol), естественно уже с частными адресами VPN-клиентов. При этом входящим/исходящими интерфейсом в iptables для этих пакетов будет тот физический интерфейс, на который подключились VPN-клиенты. Поэтому на этом интерфейсе будут одновременно "видны" как пакеты c частными адреcами VPN-клиентов, так и пакеты других интернет-соединений с публичными адресами. При этом пакетов самого туннеля (delivery protocol) в iptables не "видно". (см. Примечание)
Исходя из того что VPN-клиентов можно рассматривать как еще одну сеть, следует что управлять доступом и трафиком VPN-клиентов к другим сетям можно абсолютно также как и в случае "обычных" физических сетей.
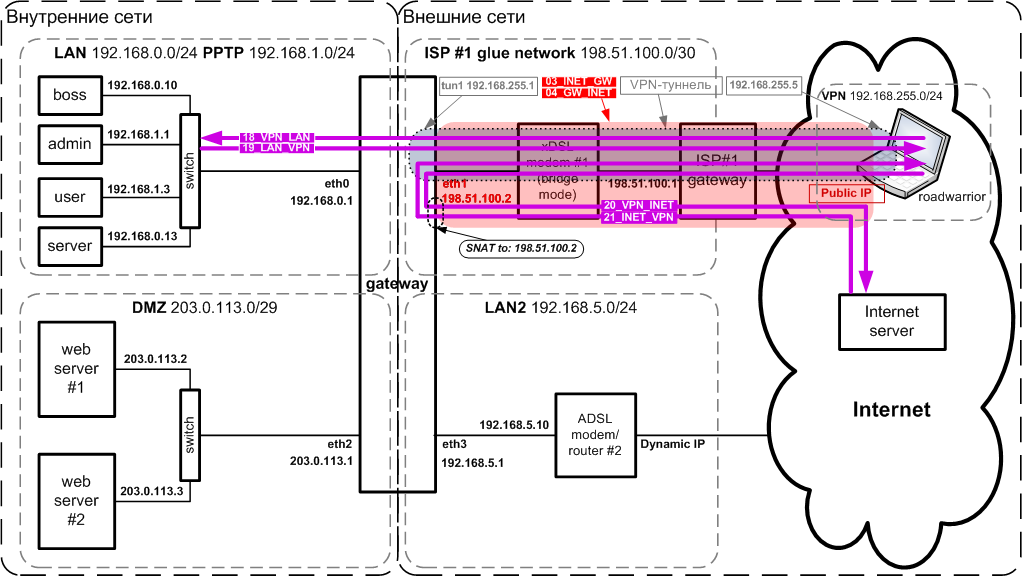
Как показано на рис. трафик между VPN-клиентом 192.168.255.5 и хостами сети LAN (payload protocol) трактуется не как Интернет-трафик, хотя VPN-клиент для нас "находится в Интернете", а как отдельный трафик между сетями VPN (192.168.255.0/24) и LAN. В свою очередь этот трафик инкапсулирован в VPN-туннель (delivery protocol) и трактуется с точки зрения фаервола как трафик Интерент-шлюз и относится к потокам INET>eth1-GW и GW>eth1-INET (цепочки потоков 18_VPN_LAN и 19_LAN_VPN).
В рассматриваемом примере VPN-клиентам выделен диапазон адресов 192.168.255.0/24. В цепочке FORWARD имеем следующие цепочки для трафика между VPN-клиентом и сетью LAN и между VPN-клиентом и Интернетом.
18_VPN_LAN all -- tun1 eth0 192.168.255.0/24 192.168.0.0/24 19_LAN_VPN all -- eth0 tun1 192.168.0.0/24 192.168.255.0/24 20_VPN_INET all -- tun1 eth1 192.168.255.0/24 !192.168.0.0/16 21_INET_VPN all -- eth1 tun1 !192.168.0.0/16 192.168.255.0/24Так как у нас нет необходимости в обмене трафиком между VPN-клиентами и внутренними PPTP-клиентами, то этот трафик и не разрешён. Цепочки же 20_VPN_INET, 21_INET_VPN как раз и нужны для случаев когда VPN-клиенту необходимо свой трафик "пропустить" не напрямую через своё подключение к Интернету, а "в обход" - через офисный шлюз, чтобы исходящие пакеты в результате NAT имели адрес шлюза. Это надо, например, если на фаерволе клиентов разрешёно подключение по RDP-протоколу только с офисного IP-адреса, а сотруднику надо подключиться к клиенту из дома. Он подключается к офисному шлюзу посредством VPN и на своём компьютере добавляет маршрут, указывающий, что к такому-то IP отправлять пакеты не через шлюз по умолчанию, а через туннель и пакеты к этому адресу начинают уходить в туннель и далее через офисный шлюз к адресу назначения.
Вкратце рассмотрим правила в цепочках 18_VPN_LAN и 19_LAN_VPN.
Видно что в цепочке 18_VPN_LAN_ALLOW у нас правила для двух VPN-клиентов:
с адресом 192.168.255.5 и с адресом 192.168.255.9.
Клиенту 192.168.255.5 разрешён доступ к своему офисному компьютеру по
RDP-протоколу (tcp dpt:3389) и напрямую к серверу по любому протоколу.
Клиенту 192.168.255.9 также разрешён доступ к своему офисному компьютеру по
RDP-протоколу и он может пинговать свой компьютер (icmp).
В цепочке же 19_LAN_VPN есть только ACCEPT...state RELATED,ESTABLISHED.
Это позволяет VPN-клиентам инициировать новые соединения на разрешённые адреса и порты,
а вот к ним из сети LAN (и других) никто подключится не сможет -
хосты сетей LAN, PPTP, DMZ не будут их "видеть". Это полезно
для того, чтобы пользователи внутри офиса не могли случайно или умышленно негативно
воздействовать на подключённых VPN-клиентов (например, взломать или заразить их компьютеры).
VPN и маршрутизация
Маршрутизация с VPN работает также как и с "обычными" сетями. Дополнительно можно заострить внимание на VPN-клиенте.
К VPN-серверу мобильный клиент подключается с помощью специального ПО - VPN-клиента, который либо уже входит в состав ОС, либо устанавливается отдельно. Само мобильное устройство, естественно, должно быть подключено к сети Интернет или иметь выход в Интернет через другие сети. Обычно выход в Интернет описывается маршрутом по умолчанию, что означает, что все пакеты для неизвестных (не описанных в таблице маршрутизиации) сетей будут уходить туда - в Интернет. В случае же использования VPN, мобильному клиенту надо выборочно направлять трафик: пакеты к определённым хостам надо направлять в VPN-туннель, а не напрямую в Интерент. Достигается это добавлением соответствующих маршрутов на компьютере мобильного клиента. При этом возможны ситуации, когда подключение к VPN-серверу прошло нормально, "всё должно работать, но не работает". Это может быть связано с вопросами маршрутизации. Рассмотрим пример.
Пусть наш сотрудник, находится в некоей организации (или домашней сети за роутером) со своим ноутбуком. Диапазон адресов сети этой организации совпадает с диапазоном адресов офисной сети - и там и там 192.168.0.0/24. Сотрудник подключает свой ноутбук к сети организации и ноутбуку присваивается адрес, допустим, 192.168.0.17. Сотрудник подключается к офисному VPN-серверу и пытается удалённо через VPN подключиться к своему компьютеру внутри офиса с адресом 192.168.0.10. Естественно ничего не получается, потому что в таблице маршрутизации его компьютера при подключении к сети, автоматически был прописан маршрут, говорящий что сеть 192.168.0.0/24 подключена непосредственно к его ноутбуку. Другими словами попытка подключения происходит к компьютеру с адресом 192.168.0.10 внутри той сети, где находится сотрудник, а не к компьютеру находящемуся в нашей офисной сети (пакеты маршрутизируются в прямо "сетевуху", а не в туннель). Т.е. надо прописать дополнительный маршрут в таблицу маршрутизации компьютера сотрудника.
Однако, если указать маршрут ко всей сети 192.168.0.0/24 через туннель, то работать ничего не будет, потому что физический шлюз организации, через который сотрудник "выходит" в Интернет и далее к VPN-серверу перестанет быть доступен. Перестанет быть доступным вообще всё: и сеть организации в которой находится сотрудник и Интернет. Ведь компьютер начнёт "пытаться пихать" в туннель любые пакеты из-за того, что шлюз для выхода в Интернет (тот который в маршруте по умолчанию) тоже находится в местной сети 192.168.0.0/24!
Правильным в этом случае является указание дополнительного маршрута не ко всей сети, а только до нужного сотруднику хоста в офисной сети. В этом случае, только трафик к этому адресу будет направляться в туннель. Естественно, этот адрес не должен совпадать ни с адресом шлюза, ни с адресом ноутбука сотрудника в местной сети. В случае, если адрес местного шлюза совпадает с адресом того хоста в офисной сети, к которому сотруднику надо получить доступ, то никакими средствами не получится получить такой доступ.
Следовательно, диапазон адресов для VPN-клиентов надо выбирать так, чтобы он с наименьшей вероятностью мог совпасть с адресами тех сетей, где предстоит находиться мобильному клиенту. В случае, если мобильный клиент подключается к Интернету напрямую, получая публичный адрес, описанной проблемы не возникает.
Выбор VPN
Выбирать будем из следующих вариантов: PPTP, L2TP, SSTP, IPSec, OpenVPN
Необходимы:
- простота в настройке;
- надежность в плане безопасности (архитектурные ошибки и уязвимости в реализации);
- 100% интероперабельность сервера с Windows-клиентами;
- возможность автоматического и ручного присвоения VPN-клиентам виртуальных IP-адресов из пула;
- работоспособность через NAT и различное сетевое оборудование;
- аутентификация по паролю и/или x.509-сертификатам;
PPTP
Слабая аутентификация. Потенциальные проблемы с прохождением протокола GRE через "кривые" маршрутизаторы (напр. Eltex NTE-RG-1402G-W с прошивками до 04.02.2011). Демон не расчитан на прослушивание разных интерфейсов с разными настройками (в т.ч. разными базами пользователей). Используя xinetd в качестве костыля, можно получить два pptp-демона с разными настройками - один слушает в LAN другой в Интернет. Однако при перезапусках такой конфигурации бывали сбои - зависело от того, к какому из них подключится первый клиент. Если в настройках pptp-демона, слушающего на Интернет-интерфейсе включить обязательное шифрование, то у pptp-клиентов в сети LAN, которые используют PPTP без шифрования, случайным образом становились недоступны различные серверы в Интернете. Причина сразу была неясна - разбираться не стал, выяснил только, что если все клиенты обоих демонов работают с одинаковыми настройками шифрования, то работает без сюрпризов. Возможно проблема связана с MTU. Макс. скорость передачи PPTP-клиента (Windows 7) по 100 Мбит ethernet-каналу чуть меньше (8-9 Мбайт/с), чем у IPSec, но с бОльшей загрузкой CPU (10-15%). Задержки (RTT) в ping больше в 3-4 раза, чем в IPSec и OpenVPN и "плавают".
L2TP
L2TP - протокол туннелирования. Не обеспечивает шифрование. Обычно в L2TP-туннель инкапсулируется PPP-трафик. В свою очередь, для защиты самого L2TP туннеля его туннелируют через IPSec. Т.е. для организации VPN на основе L2TP надо конфигурировать в три раза больше сущностей чем в IPSec: L2TP, PPP и IPSec. Уж проще тогда использовать "голый" IPSec или OpenVPN.
SSTP
Протокол от Microsoft для туннелирования PPP или L2TP через SSL: IP(TCP(SSL(SSTP(PPP-payload)))). Во время аутентификации payload-протокол еще и в HTTP "заворачивается". SSTP-сервера для Linux не существует. Т.о. пользоваться этим "чудом" реально только на продукции Microsoft.
IPSec
KLIPS - первый стек IPSec проекта FreeS/WAN для Linux версий 2.4 и 2.6.
NETKEY - "родной" IPSec стек ядра Linux версий 2.6 и 3.
Для userspace (IKE-демоны, библиотеки и утилиты) существуют:
- "родные" утилиты ipsec-tools (порт KAME project);
- FreeS/WAN - уже закрытый проект из которого были форкнуты OpenSWAN и strongSWAN;
- strongSWAN;
- OpenSWAN;
Для подключения к IPSec-серверу нужен клиент под Windows (ясно что под Linux всё родное). Мне известен только один бесплатный IPSec клиент - Shrew Soft VPN Client. В текущей версии 2.x поддерживается только IKEv1. Разработка версии с поддержкой IKEv2 не предвидится. Shrew Soft VPN Client хорошо взаимодействует с ipsec-tools и strongSWAN.
В Windows 7 есть встроенная поддержка IKEv2, но установить туннель из Windows 7 с ipsec-tools или strongSWAN так и не удалось предположительно из-за сертификатов. Правда с этими же сертификатами Shrew Soft VPN Client успешно подключался к ipsec-tools (IKEv1-демон racoon) и к strongSWAN (IKEv1-демон pluto), но, видимо, у Microsоft свои недокументированные особенности.
Вот что показала проверка реальной работы.
У ipsec-tools обнаружился недостаток - IKE-демон racoon не позволяет задать определённому клиенту определённый виртуальный IP (адрес клиентской части туннеля). Из-за этого невозможно указать правила фаервола для конкретных клиентов (сотрудников). Выснилось, что этот функционал можно реализовать с использованием RADIUS-сервера, однако, как случайно выяснилось в переписке, в Debian IKE-демон racoon скомпилирован без поддержки RADIUS-сервера, и изменений не предвидится (см. здесь и здесь) Работа через NAT не проверялась.
Сколько нибудь внятную документацию OpenSWAN и информацию о совместимости с другими реализациями на сайте www.openswan.org найти не удалось.
strongSWAN лучше документирован авторами, имеет более зрелую реализацию IKEv2 и активнее развивается. И из рассматриваемых реализаций IPSec, только strongSWAN формально отвечает всем требованиям, перечисленным в начале раздела. Однако от strongSWAN (и от IPSec) пришлось отказаться, так как в результате тестов с подключением клиента из-за NAT (Linux box и DLink DIR-300) выяснилось, что туннель создаётся, но через пару секунд "отваливается". При "прямом" (без NAT) подключении к strongSWAN всё отлично работало. Eстественно NAT-Traversal и всё что надо для его работы (открытые порты) при этом было включено и настроено. Короткая переписка с авторами strongSWAN и Shrew Soft VPN Client (см. ниже) ничего так и не прояснила. Позже появилась непроверенная догадка, что проблема как-то связана с MTU.
В ходе настройки, выяснилось, что настройка IKEv1 демона для IPSec довольно муторное дело, так как без опыта, по логам трудно понять что не так и в чём именно ошибка настройки. У strongSWAN (pluto) довольно информативные логи в сравнении с net-tools (racoon). Основные проблемы возникали из-за ошибок при генерации сертификатов.
Производительность IPSec оказалась самой высокой: около 10 Мбайт/с на 100 Мбит ethernet-канале при самой низкой (2-3%) загрузке CPU на клиенте.
http://tiebing.blogspot.com/2011/06/fairly-new-comparison-of-openswan-and.html
http://www.installationwiki.org/Openswan#Choosing_the_Kernel_IPsec_Stack
OpenVPN
Так как мне не удалось заставить IPSec работать в случае нахождения мобильного клиента за NAT'ом, то остался последний вариант - OpenVPN, который собственно и используется.
Всех вышеперечисленных недостатков у OpenVPN нет, но есть свои собственные. В ОС Windows подключиться из под пользователя без административных прав, из идущего в комплекте GUI-клиента не получится - OpenVPN не сможет создать TAP-устройство и прописать новые маршруты. Для подключения из под пользователя без административных прав предлагается запускать сервис (службу OpenVPN Service). Однако при этом теряетcя возможность управления openvpn через штатный GUI-клиент - ни отключиться, ни подключиться, ни посмотреть статус. Кроме того, при старте службы opevpn автоматически подключается ко всем сконфигурированным серверам, что не всегда удобно. Неудобная схема присвоения адресов концам туннеля, используемая для совместимости с TAP-Win32 драйвером. Производительность ниже чем у PPTP и IPSec: около 5-6 Мбайт/c при 20% загрузке CPU клиента (Celeron 2.4). Наблюдалось полное блокирование (непрохождение) трафика через туннель при 100% загрузке CPU (Celeron 2.4) другими процессами, чего не наблюдалось с PPTP (у PPTP просто раза в 4 увеличивался "пинг").
Учет (подсчет) трафика (traffic accounting)
Был выбран вариант, использующий счетчики NETFILTER. В нужные цепочки вносятся правила для счетчиков. С помощью cron, каждую минуту счетчики в этих цепочках сохраняются в файлы перенаправлением вывода команды iptables -nvxL цепочка в файл в имени которого содержится имя потока, дата и время. Таким образом за сутки создается 1440 файлов с поминутной историей значений счетчиков. Файлы сгруппированы в каталоги по годам, месяцам и числам.
По прошествии отчетного периода, неактульные данные упаковываются в архив, а оригинальные файлы удаляются.
Т.о., если не было перезагрузок, то подсчет трафика сводится к следующему:
- находим значение счетчика в строке с нужным IP в файле, соответствующем концу интересующего периода
- находим значение счетчика в строке с нужным IP в файле, соответствующем началу интересующего периода
- вычитаем из более позднего значения счетчика более раннее - получаем расход за период.
С учётом перезапуска фаервола или перезагрузок шлюза алгоритм несколько усложняется - необходимо учитывать сброс счётчиков. Возможны два варианта: либо как-то явно помечать факт перезагрузки, либо в процессе подсчета трафика анализировать сохраненные показания счетчиков, "ловя" момент обнуления счетчиков по сохранённым показаниям.
Несмотря на то, что есть возможность сохранить правила фаервола вместе с показаниями счетчиков в файл, а затем восстановить эти правила, также, вместе со значениями счетчика. Однако этим крайне нетривиально воспользоваться в случае изменения набора правил. См. скрипт conf.d/main/ta/print_inet_lan_counters в исходниках.
ДОПИСАТЬПодсчет трафика с помощью conntrackd
На момент начала созадния данного текста conntrack-tools не были доступны в стабильной версии в Debian 5 Lenny. Изучить данный вопрос. http://conntrack-tools.netfilter.org/manual.html#what.
Подсчет трафика с помощью ulogd
Когда ulogd 2-ой версии будет в Debian.
Учет трафика и SQUID
Ситуация с учетом трафика при использовании прокси-сервера на шлюзе схожа с ситуацией управлением трафиком: клиенты внутренних сети получают трафик не напрямую, а опосредованно - через squid, что затрудняет подсчет трафика средствами NETFILTER.
Без веб-прокси трафик между сетями мы подсчитываем в цепочке FORWARD, так как он проходит через шлюз от одного интерфейса к другому. В случае же использования веб-прокси, уже squid будет получать трафик из Интернета (цепочка INPUT) и затем отдавать его клиентам (цепочка OTUPUT).
Поэтому, на уровне NETFILTER, возникает сложности с определением адресов источников и получаетелей трафика. В случае использования squid пакеты, приходящие на шлюз из Интернета, будут иметь адрес назначения равный адресу самого шлюза, a пакеты, отправляемые squid'ом клиентам, будут иметь адрес источника равный адресу самого шлюза. Из-за этого, средствами NETFILTER, крайне затруднительно определить реальные адреса назначения.
В случае, если хотим поставить счётчики NETFILTER в INPUT eth1, eth3, то встает проблема определения адреса клиента, для которого squid скачал пакет. Так как пакеты приходят на адрес шлюза, а не напрямую на адрес клиента, то определить адрес истинного получателя трафика можно только анализируя HTTP-заголовки, что затруднительно на практике и негативно влияет на производительность.
Существует Application Layer Packet Classifier for Linux (L7-filter), позволяющий с помощью шаблонов из регулярных выражений с довольно высокой степенью вероятности определить к какому прикладному протоколу (уровень 7 модели OSI) относится трафик. Однако этого недостаточно, ведь надо определить не просто протокол, а выделить из каждого HTTP-заголовка IP-адрес клиента. Лобовым решением было бы создание индивидуального шаблона, включающего сам IP-адрес для каждого клиента, но очевидно, что это крайне неэффективный вариант. Опять же использование данного фильтра требует патчить и компилировать ядро и iptables. Т.о. использование L7-filter не подходит для решения данной задачи. Остаются два рабочих варианта подсчета трафика: подсчет трафика отдаваемого squid'ом и подсчет трафика пол логам squid'а.
Для подсчета трафика, который squid отдаёт клиентам внутренних сетей, счетчики можно разместить OUTPUT eth0, ppp+. В этом случае необходимо отличать трафик взятый squid'ом из своего кэша, от трафика полученного из Интернета. Сделать это можно с помощью поля TOS IP заголовка, это описано в разделе "Вариант №2: косвенное влияние на использование канала SQUID'ом плюс частичная "интеграция" с traffic control". Кроме того, подсчёт в этом варианте будет давать слегка завышенные результаты, из-за того что squid будет добавлять в HTTP-заголовки передаваемых клиентам пакетов дополнительны данные.
Вариант с подсчетом трафика по логам squid'а сводится к парсингу access-логов с информацией о каждом HTTP-ответе (адрес клиента и размер). Далее полученная таким образом информация о количестве трафика для каждого клиентского IP суммируется с данными, полученными с помощью счётчиков iptables. В результате получается суммарный (через squid + весь остальной) трафик для каждого IP.
В данном примереи спользуется вариант с подсчетом трафика по логам squid'а.
См. скрипт conf.d/main/ta/print_inet_lan_counters в исходниках.
Использование ipset. Оптимизация набора правил
Модуль ipset позволяет в одном правиле iptables эффективно выполнить проверку не по одному адресу и/ или порту (как в -s/-d и --dport/--sport), а по (большому) списку адресов и/или портов. Для этого создается нужное кол-во таблиц ipset, которые заполняются проверяемыми IP адресами и/или портами. Далее созданные таблицы используются в командах iptables для проверки соответствия с помощью '-m set --match-set setname', где setname - имя таблицы. В рассматриваемом примере с помощью ipset можно сделать следующие оптимизации.
В INPUT заменить два правила
03_INET_GW_ISP2 all -- eth3 * !192.168.0.0/16 192.168.5.1 03_INET_GW_ISP2 all -- eth3 * !192.168.0.0/16 198.51.100.2на одно, предварительно создав таблицу и заполнив её dst-адресами 192.168.5.1 и 198.51.100.2.
В рассматриваемом примере используется такое понятие как "адреса сети Интернет" которыми в данном случае удобно считать все остальные адреса кроме, адресов локальных сетей. Т.о. "Интернетом считается" всё что НЕ 192.168.0.0/16. Однако, если в локальных сетях одновременно будут использоваться адреса из разных диапазонов (10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16), то такой простой вариант указания того, что такое "Интернет" в правилах iptables не пройдет. Надо будет либо делать отдельную цепочку со списком сетей, считающихся локальными, и делать все проверки по этой цепочке, либо делать список этих сетей в таблице ipset и вставлять проверку по этой таблице в нужные правила вместо ! -d/s 192.168.0.0/16.
Далее, можно во всех цепочках *_ALLOW,*_SKIP_OR_DENY, *_SKIP_OR_DENY заменить последовательности правил с проверкой IP-адресов и портов на правила с проверкой по таблицам ipset. Фактически, c использованием таблиц ipset становятся лишними сами цепочки *_ALLOW,*_SKIP_OR_DENY, *_SKIP_OR_DENY: переходы в соответствующие цепочки можно заменить на правила с проверкой по соответствующим таблицам ipset. Такой вариант приведет к значительному уменьшению общего количества правил. При этом изменение настроек фаервола будет сводиться, в основном, к изменению ipset-таблиц, а не к удалению/добавлению правил iptables.
В рассматриваемом варианте ipset не используется в связи с тем, что в Debian модуль ipset не входит в стандартное ядро.
Для установки модулей ядра ipset можно воспользоваться пакетом module-assistant и с помощью него автоматически скомпилировать и установить пакет xtables-addons-source, в который входит и модуль ipset.
К сожалению для компиляции xtables-addons-source устанавливается компилятор, заголовки ядра и много еще чего, совершенно не нужного на шлюзе и вообще на сервере, находящемся в эксплуатации. Лучше иметь отдельную машину с архитектурой идентичной шлюзу для компиляции с последующим копированием скомпилированого пакета не шлюз. Процедура не очень удобна.
Использование -m multiport для нескольких tcp/udp портов.
iptables-restore: атомарная загрузка набора правил
Одна из особенностей NETFILTER и iptables заключается в следующем: при внесении любых изменений в активный (находящийся в ядре) набор правил с помощью команды iptables происходит копирование существующего набора правил из kernelspace в userspace, далее вносятся изменения и измененный набор загружается обратно в ядро. Поэтому при таких, инкрементальных обновлениях правил, возможны следующие негативные эффекты.
Первый эффект заключается в замедлении загрузке новых и обновлении уже существующих правил: 1-ая команда iptables обрабатывается и загружается в ядро. При выполнении второй команды, сначала из ядра загружается существующий набор правил (состоящий пока из одного правила), этот набор парсится, в него добаляется второе правило и новый набор из двух правил загружается в ядро. При выполнении 3-ей команды происходит то же, но из ядра уже загружается и обрабатывается больше информации: два правила. Далее, к этим двум правилам добавляется третье и новый набор правил снова загружается в ядро. И с каждой следующей командой между kernelspace и userspace надо прогнать и пропарсить всё больше информации. Это занимает какое-то время. Поэтому когда правил становится много, то замедление загрузки и обновления правил (время выполнения всего набора команд iptables) становится ощутимым.
Второй отрицательный эффект конфигурирования фаервола инкрементальными командами заключается в следующем. Нередко, набор правил NETFILTER имеет такую структуру, что при загрузке только части правил из всего логически связанного набора, фаервол может работать неполноценно. Так как правила добавляются по одному, а в промежутках времени между загрузками каждого из правила ядро продолжает обрабатывать пакеты согласно частично загруженному, но логически неполному набору правил, то фаервол может, например, пропускать нежелательный (разрешащие правила уже загружены, а запрещающие исключения из этих правил - еще нет) или не пропускать разрешённый трафик (удалили все правила в цепочке/таблице для полного их перестроения согласно новой конфигурации).
Чтобы избежать указанных выше проблем необходимо для начальной загрузки и обновления правил в NETFILTER использовать вместо iptables команду iptables-restore. Команда iptables-restore загружает всю группу команд для одной таблицы, переданную ей на стандартный вход, за один приём (в транзакции). Поэтому исключаются ситуации, когда только часть правил загружена в таблицу, а оставшася часть правил не загружена из-за возникшей в процессе обработки правил синтаксической или другой ошибки. Набор правил в котором обнаруженая та или иная ошибка просто не загружается в соответсвующую таблицу и имеющийся в ядре набор правил остаётся нетронутым.
В NETFILTER четыре таблицы: raw, filter, mangle, nat и все они загружаются независимо друг от друга. Возникновение ошибки при загрузке в одну из них не вызывает отката изменений в остальных.
Синтаксис команд, которые принимает на вход iptables-restore слегка отличается от синтаксиса iptables.
Структура входных данных для iptables-restore:
*таблица #1 команда #1 ... команда #N COMMIT *таблица #2 команда #2 ... команда #N COMMIT EOFСначала указывается таблица, затем перечисляются правила, вносимые в эту таблицу и завершается блок командой COMMIT.
Команда создания новых цепочек выглядит так:
:имя_цепочки - [кол-во пакетов:кол-во байт]Остальные команды (добавление, удаление, вставка и т.п.) идентичны по синтаксису параметрам команды iptables. Т.о. файл с командами для iptables-restore может выглядеть так:
*filter :DMZ_INET - [0:0] -A DMZ_INET -m state --state RELATED,ESTABLISHED -j ACCEPT -A DMZ_INET -p tcp --dport 80 -m state --state NEW -j ACCEPT COMMIT *nat :LAN_INET - [0:0] -A LAN_INET -o eth1 -j SNAT --to-source 44.44.44.44 COMMIT
По умолчанию iptables-restore полностью очищает указанные таблицы от имеющихся там правил, однако если нам надо внести изменения, не очищая существующие в ядре правила, то надо указать ключ --noflush.
nftables: преемник iptables и будущее Linux firewall
nftables - написанная "с нуля" система управления фильтрацией и классификацией трафика, призванная заменить iptables. Изначально nftables разрабатывал Patrick McHardy, сопровождающий подситему NETFILTER. Презентация проекта (включая реализацию подсистемы ядра) состоялась на Netfilter Workshop в сентябре 2008 года. 18 марта 2009 Patrick анонсировал первый публичный релиз nftables (http://marc.info/?l=linux-netdev&m=123735060618579), содержащий реализацию пространства ядра (kernelspace) и утилиту пространства пользователя для администрирования. Официальная страница проекта http://netfilter.org/projects/nftables/index.html По логу git'а (http://git.netfilter.org/nftables) можно судить о том, что релизов не было уже 4 года, но работа над проектом продолжается. На данный момент ведущим разработчиком, продолжившим развитие nftables является Pablo Neira Ayuso. Уже начата интеграция с кодом ядра в отдельном репозитарии (см. http://git.kernel.org/cgit/linux/kernel/git/pablo/nftables.git). Xtables2 vs. nftables
При разработке nftables учтены недостатки iptables. Например, "одно правило - одна цель", когда для логирования (-j LOG) и последующего игнорирования (-j DROP) пакета надо создавать два отдельных идентичных правила. При добавлении новых расширений в iptables их надо реализовать и в userspace и в коде ядра. Код ядра, отвечающий за фильтрацию содержит много дублирущегося функционала. Неэффективность инкрементальных изменений: iptables загружает из ядра весь набор правил в userspace, модифицирует его, и затем загружает весь набор обратно в ядро. Это происходит при каждом вызове iptables: в скрипте с 300-ми вызовами команды iptables описаная операция будет выполнена 300 раз, при этом с каждым разом будет расти количество информации, передаваемое между ядром и утилитой iptables. Для решения этих и множества других проблем nftables имеет следующую архитектуру.
В ядре реализована простая виртуальная машина (интерпретатор), которая имеет инструкции для загрузки данных из пакета, поддерживает выражения для сравнения различных частей пакета (по смещениям) с чем-либо, инструкции отслеживания состояний (limit, quota, ...) и т.д. Это освобождает от "зашитой" в код ядра информации о протоколах и о том как их анализировать: мы просто программируем ВМ ядра на выполнение тех или иных программ по обработке пакетов прямо из userspace. Подобным же образом в BSD-системах давно и успешно реализован BSD Packet Filter. Это позволит, не затрагивая ядро Linux, разрабатывать новые (исправлять существующие) правила обработки для новых протоколов, что очень сильно упрощает процесс и избавляет от дублирования кода в kernelspace и userspace.
nftables поддерживает такие структуры данных как множества и словари, что позволяет в одном правиле выполнять различные проверки по спискам и диапазонам значений (аналогично ipset, но с любыми данными). Код ядра полностью свободен от блокировок (locks). Счетчики пакетов и байтов, в отличие от iptables, опциональны, т.е. их нет по умолчанию в каждом правиле, их надо создавать явно. Это положительно влияет на производительность. Нет встроенных таблиц - все таблицы надо явно объявлять. Ядро выполняет минимальные проверки и не проверяет (смысловую) корректность загружаемых в ВМ программ, лишь бы программа не повредила ядро: все синтаксические и семантические проверки дожны проводиться утилитами userspace.
Соответственно, вместо последовательности команд iptables с ключами, для nftables существует полноценный высокоуровневый язык, который компилируется в низкуровневые инструкции для ВМ ядра. С помощью userspace утилиты nft можно выполнять как отдельные команды этого языка, для инкрементальных изменений, так и целые программы, написанные на этом языке. Т.о. сложной последовательности команд iptables по созданию цепочек и правил в этих цепочках, в nftables будет соответствовать программа состоящая из одного или нескольких файлов. Утилита nft проверит синтаксис этой программы, сообщит об ошибках, откомплирует её в инструкции ВМ и загрузит откомпилированую программу в ВМ ядра, используя протокол netlink.
Часть 2. Реализация
Эта часть посвящена описанию реализации фаервола, написанного с учетом принципов и требований первой части. Естественно рассматриваемый вариант является лишь одним из возможных подходов к решению этой задачи со своими преимуществами и недостатками.
Описанный вариант фаервола можно использовать непосредственно, без переделок, либо скорректировать его под свои нужды (в первую очередь по кол-ву интерфейсов на шлюзе и используемых сетей).
При реализации фаервола возникли вопросы вроде:
- на каком язык писать?
- как реализовать настройку (формат, назначение, кол-во файлов)?
- как структурировать сам код и др. файлы?
Будет рассмотрено как эти вопросы были решены в данной реализации.
Чем не устроил Shorewall
На момент проб Shorewall был 3-ей версии. Пробовал я его на "Web server #1" в DMZ. В частности необходимо было задать различные наборы правил для клиентов из сети INET и cети LAN2, подключенных через eth3. Из INET надо было ничего не разрешать, а из LAN2 дать доступ к DMZ. Но я так и не смог настроить Shorewall так, чтобы он "понимал" что за интерфейсом eth3 у меня две сети, для каждой из которых я хочу настроить разные правила. На все мои варианты Shorewall сообщал об ошибке в конфигурации: что именно было уже не помню - что-то про нестыковку в сетях (файл hosts) и интерфейсах (файл interfaces). Т.е. добиться того что мне надо от Shorewall я так и не смог, и чем мучаться и догадываться что там не так я вручную написал эти несчастные несколько нужных мне правил.
Также мне не понравился формат конфигурационных файлов: в частности большой объем правил в rules читается с трудом. И в файл не предусматривает встраивания метаданных об хостах сети для последующего из использования в отчетах. Можно было метаданные вставлять в виде комментариев, но мне этот вариант не понравился.
Потом я поверхностно посмотрел, какие правила и цепочки генерировал Shorewall, в надежде понять как же добиться от него того, что мне надо, однако никакой системы на тот моментя там не уловил - все правила "валились в кучу": в INPUT, FORWARD, OUTPUT. Помню была некая специальная цепочка "all2all" и всё.
Вообщем смысл вышексказанного сводится к тому, что написать нексолько правил для той задачи было гораздо проще, чем тратить время на разбор того, почему у меня не получается добиться того же результата от Shorewall и я плюнул на него, в том числе чтобы знание устройства Shorewall не повлияло на то, как я буду делать свой велосипед.
На 2013 год Shorewall имеет 4 версию, которая переписана на Perl вместо Bash, но синтаксис конфигурационных файлов остался прежним. Интересно, изменилось ли что-то в логике построения цепочек и правил.
Предыдущие варианты реализации или "как не надо делать"
В своё время, я не знал о существовании, например, shorewall и поэтому "изобретал велосипед" заново, не зная на каких принципах построены другие firewall'ы. Позже я попробовал использовать shorewall 3-ей версии на веб-сервере в DMZ, но так и не добился того, что мне было нужно и не стал разбираться - возможно ли это в приниципе. Поэтому изобретение велосипеда продолжилось.
Ниже описаны варианты фаервола, предшествововашие рассматриваемому варианту. Это сделано с целью поделиться опытом и показать "как не надо делать". Условно, рассматриваемый в данном тексте вариант фаервола можно считать "четвертой версией". А вот предыдущие три:
"Версия №1" - это просто bash-скрипт, содержащий линейную последовательность команд iptables..., выполнение которых и конфигурировало NETFILTER. Скрипт не имел настроек или параметров и для вненсения изменений, надо было исправлять непосредственно сам скрипт. По мере добавления новых интерфейсов и расширения функционала, рос и объем скрипта. Скрипт становился плохо управляемым и нечитаемым. Управления трафиком не было в принципе - вообще непонятно было как это делается. Назрела переделка.
"Версия №2". Первоначальный bash-скрипт был переписан: за конфигурацию правил каждого из потоков теперь отвечала отдельная функция в этом скрипте. Имелся файл настройки: отдельный bash-скрипт, в котором были описаны одномерные массивы в которых указывались списки (через пробелы) разрешённых IP- адресов и/или портов. Массивов было много - для каждого из потоков и для каждого типа задач (глобальные/индивидульные/адреса/порты/протоколы разрешения, запреты, исключения) приходилось заводить свой массив. Индексами в этих массивах были последние октеты IP-адреса хостов внутренней сети (напр. LAN_IP_INET_IP_ALLOW[131]="0.0.0.0/0" описывал разрешение хосту 192.168.0.131 на выход в Интернет). В рабочем скрипте использовалось множество однотипных циклов по этим массивам: так строились наборы правил для каждого из потоков. В скрипте, в достаточном количестве, присутствовали "ручные вставки кода" для "для решения особых случаев". Такая система была неуниверсальна, привязана к сети класса С и громоздка (для каждой из сетей приходилось заводить свои наборы массивов).
На этом этапе возникла необходимость в управлении трафиком и отчетности. Т.е. в конфигурации надо было увязать IP-адреса и некие метаданные (ФИО сотрудников, названия серверов) и как-то интегрировать это с управлением трафиком. Вопрос интеграции метаданных был решен примитивно - так как срипт отчетности был написан на perl'е, то для него просто вёлся отдельный perl-скрипт c хэшем IP-адресов, в котором хранились нужные данные. Ясно что возникло дублирование данных (IP-адресов) в двух файлах: в конфигурационном bash-скрипте, предназначенном для фаервола и в конфигурационном perl-срипте предназначенном для отчетности.
Управление трафиком было реализовано также примитивно: отдельный фиксированный bash-скрипт, в котором указывалось download-скорость из Интернета в LAN. Для ppp-клиентов был отдельный скрипт. Дублирование конфигурационной информации нарастало. Позже эта версия была слегка модифицирована: один единый файл конфигурации (bash-скрипт) был разбит на отдельные файлы (по кол-ву потоков), в каждом из которых содержались настройки, относящиеся только к данномоу потоку. Единый основной скрипт также был "расчленён" по тому же принципу - "каждому потоку - свой скрипт", в каждом файле две функции: для правил трафика "туда" и для правил "в обратном направлении". В результате получилась довольно негибкая "смесь" из различных подходов, которая не обладала нужной "полноценностью" (управление трафиком, ау!) и снова была слабоуправляемой. Необходимо было превратить эту "кашу" в нечто более стройное и единообразное. Основные направления: унификация формата настройки, его расширямость, читаемость и некая универсальность. И как следствие - неизбежный уход от bash, в сторону языка, с поддержкой болеес сложных структур данных.
"Версия №3". В этой версии файлы настроек были уже написаны на perl как и сам firewall. Однако ж снова, на каждую пару потоков было по своему собственному скрипту и для каждого потока был свой настроечный файл. Предполагалось, что при необходимости, нужные скрипты и конфигурационные файлы будут дописаны, используя существующие, как шаблоны.
Однако с конфигурационными файлами возникла следущая проблема - их было два вида: один для описания потоков типа "шлюз-сеть"и другой для потоков тип "сеть-сеть". И кроме того, был конфигурационный файл, описывающий хосты (фактически пользователей) сети LAN, со своими особенностями (метаданными). А хотелось иметь один универсальный "формат". Остановлюсь на этом моменте подробнее. Кроме того, "специализированные" скрипты для каждого из потоков сами по себе плохое решение.
Что должны описывать конфигурационные файлы.
Поэтому встал вопрос о том, как организовать информацию в конфигурационных файлах. Здесь усматривается два типа информации, которую надо хранить:
- информация непосредственно об хостах сетей: адреса, имена, скорости и прочая вспомогательная информация, характеризующая данный узел; и
- информация о связях между хостами какой-либо пары сетей: какой между ними трафик разрешён, запрещен и т.п. (т.е. правила, говорящие что может передавать один узел другому)
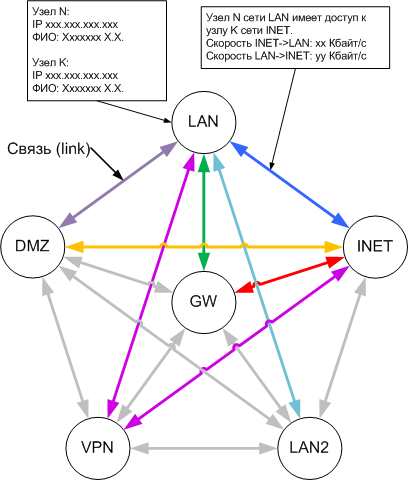
Следующий вопрос: в какое количество файлов и каким именно образом сгруппировать данную информацию? Варианты:
- два типа конфигурационных файлов: один тип описывает непосредственно хосты некоей сети и их метаданные, а другой - только "связи" между ними хостами этих сетей ("что разрешено или запрещено"); тогда, например для двух сетей небохидимы три файла: первый описывает хосты одной сети, второй описывает хосты другой сети и третий файл описывает связи между ними; общее кол-во файлов равно сумме числа всех хостов и числа всех связей
- один тип конфигурационных файлов, описывающий "связи" между хостами двух произвольных сетей; при этом информация о самих хостах хранится в описании самой "связи"; в данном варианте общее кол-во файлов равно сумме числа всех свзяей между хостами
- один тип конфигурационных файлов, совмещающий описание хостов и связей в виде некоей иерархической структуры;
У первого варианта два существенных недостатка: необходимость в двух форматах файлов конфигурации и неудобство управления двумя видами файлов. При изменениях конфигурации надо будет вручную сверять эти файлы на наличие несоответствий между наличием (отсутствием) связей в одном файле и наличием (отсутствием) описания соответсвующих этим связям хостов в другом файле.
Недостаток второго подхода - дублирование информации об хостах: так как нет специального файла, в котором один раз были бы описаны хосты, то эту информацию надо будет в описании каждой "связи" между разными сетями, даже если с одной стороны связи один и тот же узел.
Третий вариант хорош, но возникает вопрос: неясно, в каком из двух файлов, описывающий хосты, размещать информацию о связях для каждой пары сетей? Решение оказалось простым: правила для трафика надо размещать в том файле, где это удобно и наглядно. Настройка должна позволять размещать правила произвольно в произвольном количестве файлов: для пары сетей можно разместить одну часть правил в одном файле, а остальные правила - в другом, а можно все правила сгруппировать в один файл.
Т.о. версия №3 фаервола просуществовала недолго и оказалась опытной площадкой для перехода на следующую, четвертую версию с унифицированным форматом конфигурационных файлов, который и рассматривается далее.
Исходные тексты фаервола
Почему perl, а не bash, python и т.д.?
Для написания фаервола рассматривались языки bash, perl и python. Для описания конфигурации и собственно кодинга выбран язык perl и вот почему.
- bash
- В bash 3.x нет сложных структур данных, а именно хэшей (словарей, ассоциативных массивов). И хотя в bash 4.x словари появились, но этого недостаточно, потому как невозможно создавать вложенные струтктуры данных: многомерные массивы, массивы хэшей, хэши массивов и т.п.
- python
- Python не является обязательным для Linux и не устанавливается по умолчанию (как минимум в Debian без GUI). Использование Python приводит к зависимости фаервола от необязательного компонента системы и необходимости устанавливать Python, потенциально, только ради работоспособности фаервола.
- perl
- Является неотьемлемой частью любого (серверного) дистрибутива. Мало того, без него невозможно скомпилировать Linux систему из исходных текстов (смотри напр. Linux From Scratch). Т.е. perl обязательно будет в любом десктопном или серверном дистрибутиве по умолчанию. В perl, в отличии от bash, есть удобные структуры данных и их легко сделать вложенными.
Т.о. был выбран perl: за присутствие в системе по умолчанию, наличие удобных структур данных и за общую гибкость в решении задач администрирования.
Почему конфигурация не хранится в СУБД или LDAP
При размещении конфигурации в СУБД или LDAP возникает зависимость от наличия этих компонентов на том хосте, где планируется использовать фаервол. Соответственно их надо установить и сконфигурировать, что может стать источником ошибок и дополнительной траты времени. Так как я стремился к абсолютному минимуму зависимостей и к наглядному, легко редактируемому формату конфигурации, то для хранения конфигурации были выбраны обычные текстовые файлы. Их леко копировать и для внесения изменений ничего, кроме текстового редактора, не требуется. Это позволяет просто скопировать фаервол на новую машину и не думать о зависимостях, установке и настройке СУБД и т.п.
Устройство фаервола
Общие замечания
- Код и настройки фаервола имеют модульную структуру. Идея заключается в том, чтобы иметь в наличии некий набор базовых действий (функций), используя которые, можно "собирать" более высокоуровневые скрипты, выполняющие уже какие-то конкретные задачи. Конечно, это далеко не абсолютно универсальные функции, позволяющие строить фаервол произвольной структуры, а функции, реализующие вполне определенный подход, описанный в первой части. (С течением времени идея выродилась, так как набора слабосвязанных скриптов сделать не получилось и все превратилось в набор функций в модуле firewall.pm)
- Код написан, а настройки расположены в файловой системе таким образом, чтобы легко было иметь несколько различный конфигураций одновременно и переключаться между ними одной командой. К тому же за счёт того, что есть возможность разбивать конфигурацию на произвольное кол-во файлов, при продуманном подходе к их написанию, возможно их повторное использование в различный конфигурациях. Например, если с 9 до 18 часов, должны действовать какие-то глобальные запреты, а в другое время эти запреты не действуют, то в основной (с 9 до 18) конфигурации можно вычленить в отдельный файл эту запрещающую часть. Далее создать новую конфигурацию, в которую слинковать часть файлов из основной конфигурации и убрать запуск обработки конфигурационного файла с запретами. И, наконец, перезапускать фаервол в нужное время с помощью crontab, указывая нужную конфигурацию.
- Не все команды для конфигурации фаервола создаются автоматически на основании файлов конфигурации. Часть команд содержится в явном виде непосредственно скриптах. Это связанно с тем что не для всех случаев легко и очевидно на данный момент или целесообразно придумывать синтаксис конфигурации и писать её обработку - иногда проще написать несколько команд, выполняющих нужные действия. В рассматриваемом варианте это относится, например, к правилам NAT: их немного, меняются они нечасто и "городить" ради них настройку и её обработку просто сложнее чем написать скрипт с несколькими командами iptables который и будет запускаться в нужный момент. Пометка трафика для целей policy routing также сделана отдельным скриптом с нужным набором правил, так как на данный момент для меня неочевидно как это гибко "вписать" в выбранную концепцию конфигурационных файлов. Но и данный вариант более чем жизнеспособен.
- Фаервол не сохраняет какой-либо метаинформации о своём текущем состоянии на диске или в памяти. После каждого изменения конфигурации требуется полная обработка конфигурации, построение структур в памяти и формирование нового набора правил.
- Сначала на основании конфигурации генерируется полная последовательность команд iptables и tc, и только затем эти команды выполняются. При возникновении оишибок во время генерации команд они просто не выполняются.
- Фаервол позволяет описать настройку как шлюза с произвольным кол-вом интерфесов и сетей к ним подключенным, так и, например, сервер или рабочую станцию, не выполняющие роль шлюза.
- Фаервол не проверяет смысловую корректность файлов настройки и конфигурации в целом. Реализация таких проверок в полном объеме - сложная и трудоёмкая задача и для проекта, используемого только в личных целях, не приоритетная. В данном случае, с помощью возможностей интерпретатора perl, проверяется только синтаксическая корректность файлов конфигурации. По этой же причине выдача различных дигностических сообщений минимальна.
- По умолчанию для каждой связи трафик потоков идущих в одном направлении, проверяется по одной и той же пользовательской цепочке. Например потоки INET>eth1-eth0>LAN, INET>eth3-eth0>LAN, INET>eth1-pppX>LAN, INET>eth3-pppX>LAN по умолчанию будут проходить проверку по одной и той же цепочке. Данное поведение изменяется доп. конфигурированием.
- Фаервол работает только с IPv4. Для IPv6 необходима соответствующая доработка (как минимум, для IPv6 надо использовать ip6tables).
Структура каталогов
В приведенных выше исходных файлах примере весь код и настройки фаервола расположены в каталоге /etc/hlf.
Код написан так, что работает по относительным путям и поэтому его можно
размещать где угодно в файловой системе.
Поэтому далее по тексту каталог в котором расположены файлы фаервола будет
обозначаться как /FW. Если для файлов и каталогов не указан полный путь,
то подразумевается их размещение относительно каталога /FW.
Итак, в каталоге /FW находятся:
- conf.d - каталог, в котором хранятся конфигурации (каждая конфигурация в своём отдельном подкаталоге);
- conf.d/allow_all - каталог с конфигурацией фаервола, которая разрешает прохождение любых пакетов;
- conf.d/block_all - каталог с конфигурацией фаервола, которая запрещает прохождение любых пакетов;
- conf.d/default - символическая ссылка на каталог с конфигурацией, используемой по умолчанию;
- conf.d/main - каталог с основной конфигурацией фаервола, которая рассматривается в данном тексте;
- conf.d/outbound_only - каталог с конфигурацией фаервола, которая разрешает прохождение пакетов только для соединений, установленных самим шлюзом;
- modules - каталог, в котором размещаются файлы, с кодом, реализующем функционал, общий для всех конфигураций (т.е. общие алгоритмы) и другие вспомогательные скрипты:
- modules/firewall.pm - модуль Perl с функциями разбора файлов конфигурации и генерации последовательности команд
- modules/fw-sysv - bash скрипт запуска для системы инициализации SysV
- modules/init - bash скрипт начальной инициализации фаервола (очистка всех таблиц)
- modules/load_modules - bash скрипт с командами загрузки необходимых модулей ядра
- modules/save_counters - bash скрипт, являющийся шаблоном, по которому создаётся файл для записи счетчиков iptables в файлы
- modules/wait_dns - bash скрипт ожидающий установления связи ADSL-модемом посредством попыток открытия порта на DNS-сервере провайдера; необходим для разрешения DNS-имен в правилах iptables, если таковые будут
- start - головной скрипт запуска фаервола.
Поддержка нескольких конфигураций (/FW/conf.d)
В каталоге conf.d может находиться произвольное количество различных конфигураций фаервола - каждая в своем отдельном подкаталоге. При этом имя подкаталога фактически является именем расположенной в нём конфигурации. Также в conf.d может находиться символическая ссылка conf.d/default, указывающая на каталог, содержащий конфигурацию фаервола, используемую по умолчанию.
Для запуска фаервола предназначен скрипт /FW/start.
Если в качестве параметра скрипту start передано имя подкаталога
из каталоге conf.d (напр. outbound_only), то будет запущен скрипт start,
находящийся в указанном каталоге.
В свою очередь, запускаемый скрипт conf.d/имя_конфигурации/start
и должен выполнить всю последовательность действий по конфигурированию фаервола для
выбранного варианта конфигурации.
Если скрипту start не передано имя конфигурации, то этот скрипт пытается
запустить скрипт conf.d/default/start, где default может быть как обычным
подкаталогом с конфигурацией по умолчанию, так и символической ссылкой на некий существующий
подкаталог conf.d/имя_конфигурации.
Данный механизм жёстко задан и не может быть изменён без правки кода в /FW/start.
Общие модули (/FW/modules)
Собственно здесь находятся общие "строительные блоки" - файлы с кодом, которые можно использовать в скриптах каждой из конфигураций. Основной из них - perl-модуль firewall.pm. Именно в нём реализованы почти все функции по конфигурированию фаервола. Его внутреннее устройство будет рассмотрено ниже.
Конфигурационные файлы
Как уже говорилось выше, фаервол поддерживает произвольное кол-во независимых
конфигураций.
Минимальная конфигурация (каталог conf.d/имя_конфигурации) включает в себя три элемента:
- start - исполняемый perl-скрипт из которого вызываются функции модуля
firewall.pm в необходимой вам в данной конфигурации последовательности,
а так же выполняются любые другие необходимые действия;
Написание данного срипта является частью процесса конфигурирования! - один конфигурационный файл, описывающий интерфейсы шлюза и сЕти, подключенные к этим интерфейсам непосредственно или которые доступны через эти сети; далее по тексту такие файлы будут обозначаться как networks.conf
- конфигурационный файл (один или несколько), описывающий метаданные, разрешающие и запрещающие правила, скоростные ограничения и т.п. как для сетей, перечисленных в networks.conf, так и для отдельных хостов в этих сетях; далее по тексту такие файлы будут обозначаться как hosts.conf.
В конфигурации фиксированное имя имеет только скрипт start. Так как содержимое скрипта start пишется индивидуально для каждой конфигруации, то и для файлов networks.conf и hosts.conf можно выбрать любые имена и расположение внутри каталога конфигурации. Кроме того, не обязательно иметь один файл типа hosts.conf - конфигурацию правил для хостов/сетей можно разбить произвольным образом на любое кол-во файлов, естественно с разными именами.
В случае необходимости используются как конфигурационные файлы, так и вспомогательные скрипты. Т.е. конфигруация может придставлять собой произвольный набор скриптов и конфигурационных файлов определенной структуры. Скрипты, в определенной последовательности, запускают какие-либо команды ОС, вызывают вспомогательные функции из общих модулей conf.d/modules, которые в свою очередь разбирают файлы конфигурации и формируют на их основе последовательность команд iptables, tc и т.п. для создания нужных цепочек, правил, задания правил управления трафиком и т.д.
Файл описания шлюза и сетей (аkа networks.conf)
Назначение данного файла - описать интерфейсы шлюза и сЕти, подключенные к этим интерфейсам непосредственно или которые доступны через эти сети. В конфигурации этот файл должен быть в единственном экземпляре. На основании этого файла определяются все возможные соединения между каждой парой сетей, между шлюзом и сетями; для соединений определяются прямые и обратные потоки, именуются цепочки и строится общий "каркас" цепочек NETFILTER (т.е. набор цепочек и переходов между ними). Также, на основании информации из этого файла строятся "головные" правила для цепочек INPUT, OUTPUT, FORWARD, с помощью которых, на основании входящих и исходящих интерфейсов и сетей, трафик относится к тому или иному потоку.
С точки зрения синтаксиса данный файл представляет собой Perl-скрипт, настройки в котором описаны в виде хэша %networks. Использование конфигурационных файлов, которые по сути являются фрагментами исполняемого языка программирования имеет недостатки:
- так как файл конфигурации фактически исполняется интерпретатором (в данном случае Perl), да еще с правами root, то в файл конфигурации можно случайно или намеренно вставить код, выполнение которого будет будет иметь побочные, возможно даже деструктивные, последствия;
- синтаксис файлов не является нейтральным по отношению к языку, на котором написан фаервол: при смене языка придется переписывать файлы конфигурации согласно новому синтаксису;
- владелец каталога /FW и всего его содержимого;
- только root может изменять и запускать файлы в /FW;
- и что он достаточно разумен, чтобы не вписать в файлы конфигурации что-то вроде `unlink '/etc/passwd'` или `system('rm -R /')`.
Далее описан синтаксис файла описания шлюза и сетей.
В качестве примера смотри файл /etc/hlf/conf.d/main/conf/networks.conf в исходниках.
Файл должен иметь синтаксис perl-скрипта. В файле должен быть один раз описан хэш с зарезервированным именем %networks. Каждый элемент хэша %networks описывает одну сеть. Ключ в %networks является именем сети и на него возможны ссылки из этого и других конфигурационных файлов. Имя сети выбирается произвольно и должно быть уникальным. В %networks должны быть описаны все сети, трафик которых проходит через шлюз и трафиком которых вы хотите управлять. Сам шлюз синтаксически трактуется как сеть и должен быть описан в данном файле.
%networks = (
сеть№1 => описание_сети,
сеть№2 => описание_сети,
сеть№3 => описание_сети,
...
сеть№N => описание_сети,
}
Описание_сети представляет собой хэш из четырех элементов со следующими ключами:
- name - наименование сети - используется при генерации имён цепочек; обязательный параметр;
- type - задает тип сети. Обязательный параметр. Возможные значения:
- host: служит для указания, что данное описание_сети описывает сам шлюз;
- net: служит для указания, что данное описание_сети описывает некую сеть;
- ifaces - для type => 'host' описывает интерфейсы с их адресами.
Для type => 'net' описывает адреса сетей (т.е. можно несколько IP-сетей трактовать как одну) и интерфейсы шлюза, через которые эти сети доступны непосредственно или косвенно. Обязательный параметр; - flows_options - описывает различные параметры потоков между данной сетью и остальными сетями. Необязательный параметр.
%networks = (
сеть№1 => {
name => наименование_сети, type => тип_сети,
ifaces => описание_интерфейсов,
flows_options => опции_потоков
}
)
Описание_интерфейсов представляет собой хэш в котором каждый элемент описывает один сетевой интерфейс. Ключом хэша является имя интерфейса в формате команд iptables. В описании шлюза (тип "host") в ifaces должны быть перечислены сетевые интерфейсы шлюза. В описании сети (тип "net") должны быть перечислены сетевые интерфейсы, через который данная сеть доступна непосредственно или далее через маршрутизаторы (next hops). При использовании алиасов (интерфейс с несколькими ip-адресами) алиас описывается как отдельный интерфейс.
ifaces => {
'eth0' => параметры_интерфейса,
'eth0:0' => параметры_интерфейса,
'eth1' => параметры_интерфейса,
'ppp+' => параметры_интерфейса,
...
},
Параметры_интерфейса представляют собой хэш из элементов со следующими ключами.
- addr - задает IPv4-адрес интерфейса (для шлюза) или сети;
- tc_iface - имя IFB-интерфейса, на который будет перенаправлен трафик данного интерфейса. Собственно перенаправление должно осуществляться дополнительно утилитой tc в пользовательском скрипте;
- tc_root_handle - номер major для дисциплины данного интерфейса - имеет смысл только в описании шлюза;
- qd_start_minor - номер minor с которого начнется нумерация автоматически создаваемых классов для дисциплины данного интерфейса. Имеет смысл только в описании шлюза
gw => {
...
ifaces => {
'eth0' => {addr => '192.168.0.1', tc_iface => 'ifb0', tc_root_handle => '0'},
'eth0:0' => {addr => '192.168.4.1'},
'ppp+' => {addr => '192.168.3.1', tc_iface => 'ifb0', tc_root_handle => '3', qd_start_minor => '30'}
}
},
lan => {
...
ifaces => {
'eth0' => {addr => '192.168.0.0/24'}
'ppp+' => {addr => '192.168.1.0/24'}
}
}
Опции_потоков (ключ flows_options) представляет собой хэш в котором каждый элемент описывает параметры одного потока или группы потоков между данной сетью и другими сетями. Понятие потока смотрите в разделе Основные концепции: потоки, линки, цепочки, в частности рис. 3.
сеть№1 => {
ifaces => {
...
flows_options => {
'сеть№2' => параметры_потока,
'сеть№3/ppp+/tun+' => параметры_потока,
'сеть№4' => параметры_потока,
'сеть№4//eth3' => параметры_потока,
'сеть№5/ppp+' => параметры_потока,
}
}
}
Так как правила и имена цепочек генерируются автоматически, то необходимо иметь
некий мехнизм управления параметрами этой генерации - опции_потоков.
Основное использование опций потоков:
- влияние на порядок головных правил в цепочках INPUT, FORWARD, OUTPUT;
- явный запрет на генерацию правил для потока(ов);
- автоматическая генерация правил-счетчиков на основе сгенерированных разрешающих правил;
- создание в таблицах filter и mangle отдельных цепочек для определённого потока или группы потоков. Данная возможность необходима в связи с тем, что по умолчанию трафик всех потоков между двумя сетями "группируется" - его проверка происходит по одним и тем же правилам в одной сгенерированной для этой цели цепочке потока.
Ключ в опции потока идентифицирует поток или группу потоков согласно следующему синтаксису:
сеть_назначения/входящий_интерфейс/исходящий_интерфейс.
Указание сети_назначения обязательно.
Отсутствие в ключе интерфейса означает "любой интерфейс" из тех, что "связывает" две сети.
Пример для потоков INET->LAN на рис. 3. Их будет четыре: INET>eth1-eth0>LAN, INET>eth1-ppp+>LAN, INET>eth3-eth0>LAN, INET>eth1-ppp+>LAN. Смотрим, как можно указать эти потоки:
inet => {
name = "INET",
...
ifaces => {
...
flows_options => {
(1) 'lan' => параметры_потока,
(2) 'lan/eth1' => параметры_потока,
(3) 'lan//ppp+' => параметры_потока,
(4) 'lan/eth3/eth0' => параметры_потока,
}
}
}
Вариант (1) задаст параметры для всех четырёх потоков. Вариант (2) задаст параметры для двух из четырёх потоков: INET>eth1-eth0>LAN, INET>eth1-ppp+>LAN. Вариант (3) задаст параметры для других двух потоков, у которых выходной интерфейс ppp+: INET>eth1-ppp+>LAN, INET>eth3-ppp+>LAN. Вариант (4) задаст параметры для только для одного потока: INET>eth3-eth0>LAN.
Параметры_потока представляют собой хэш из элементов со следующими возможными ключами:
- order - строка, добавляемая в начало имени цепочки, генерируемой для данного потока(ов). Используется в случае необходимости задать порядок правил, генерирумых для цепочек INPUT, FORWARD, OUTPUT. Правила будут созданы в алфавитном порядке имен цепочек;
- ban - явный запрет на генерацию правил потока. Допустимы два значения:
- flow - запрещает генерацию любых цепочек и правил для данного потока(ов). Пример. Между сетями VPN и LAN связь возможна через два LAN-интерфейса: eth0 и ppp+. Известно что трафик между VPN и LAN через ppp+ не нужен. Т.е. необходимо полностью запретить потоки VPN>tun1-ppp+>LAN и LAN>ppp+-tun1>VPN;
- rules - разрешает генерацию цепочки потока и stateful-правил RELATED,ESTABLISHED, но запрещает генерацию любых пользовательских правил для данного потока(ов); Пример. Новые соединения между сетями DMZ и LAN должны быть возможны только в одном направлении: из сети LAN в DMZ, но не наоборот. Если для потоков DMZ->LAN указать ban => 'flow', то любые правила для этих потоков будут проигнорированы, что застрахует от случайного разрешения новых соединений из DMZ в LAN;
- filter_chain - задает имя цепочки в таблице filter, которое будет использовано при генерации правила для данного потока(ов). В частности, таким образом можно задать разный набор правил фильтрации для потоков, которые по умолчанию проверяются по одной и той же цепочке. Пример. Все потоки LAN>INET проверяются по одной цепочке 05_LAN_INET. Чтобы часть потоков идущих через eth3 проверялась по набору правил, отличному от правил для потоков идущих через eth1, можно для потоков LAN>*-eth3>INET задать имя цепочки потока, отличное от автоматически сгенерированного '05_LAN_INET'. А в правилах для этого потока дополнительно уточнять исходящий интерфейс eth3.
- mangle_chain - задает имя цепочки в таблице mangle, которое будет использовано при генерации правила для данного потока(ов). Использование аналогично filter_chain. Чтобы выполнить классификацию трафика для потоков LAN>*-eth1>INET не так как для LAN>*-eth3>INET можно задать мия для этих потоков.
- count - разрешает автоматическую генерацию счетчиков на основе
разрешающих правилам потока(ов). Допустимы три значения:
- direct - вызывает генерацию правил-счётчиков в данном потоке по разрешающим правилам для данного потока;
- back - - вызывает генерацию правил-счётчиков в обратном потоке по разрешающим правилам для данного потока;
- both - вызывает генерацию правил-счётчиков в данном и обратном потоках по разрешающим правилам для данного потока;
Пример, чтобы было понятнее про параметр count.
В сети LAN есть хост с адресом 192.168.0.13 и ему разрешён доступ в сеть INET (Интернет).
Для этого в цепочку потока 05_LAN_INET добавляется ALLOW-правило с адресом источника
192.168.0.13.
Теперь необходимо посчитать сколько данный хост получает трафика из сети Интернет (входящий трафик). Трафик к этому хосту из сети Интернет идет в обратном направлении и проверяется по цепочке 06_INET_LAN обратной для 05_LAN_INET. Естественно правила-счетчики для подсчёта необходимо вставить в цепочку 06_INET_LAN (а не 05_LAN_INET), да еще и адрес 192.168.0.13 указать в назначении, а не в источнике. Вот такие правила и генерируются при count => 'back'. Другими словами: "сгенерируй для адреса, которому мы разрешили выход в сеть, правила для подсчета трафика, получаемого им из этой сети".
Если необходимо подсчитать исходящий трафик для 192.168.0.13, то правила естественно надо размещать в 05_LAN_INET, т.е. в той же цепочке, где и само разрешающее правило. Для этого используется count => 'direct'.
И наконец, если для хоста 192.168.0.13 необходимо подсчитать и исходящий и входящий трафик, то ставим count => 'both' и счетчики для 192.168.0.13 генерируются для 192.168.0.13 в обоих цепочках: в 05_LAN_INET с src 192.168.0.13, а в 06_INET_LAN с dst 192.168.0.13.
Файл описания правил для хостов и сетей (аkа hosts.conf)
Назначение данного файла - описать метаданные, разрешающие и запрещающие правила, скоростные ограничения и т.п. как для отдельных хостов какой-либо сети из указанных в networks.conf, так и, возможно, для сети в целом. В конфигурации количество файлов hosts.conf может быть произвольным и не обязательно совпадать с количеством сетей, описанных в networks.conf: код конфигурации написан так, что правила можно группировать и размещать в произвольном количестве файлов типа hosts.conf.
Например, можно использовать один файл net.conf, в котором будут описаны абсолютно все правила, можно использовать несколько файлов net.conf - по одному на сеть, можно сгруппировать правила в разные net.conf по отделам, кабинетам или по как-либо другим признакам.
С точки зрения синтаксиса данный файл также представляет собой Perl-скрипт, настройки в котором описаны в массиве @items. О плюсах и минусах такого подхода см. выше.
Далее описан синтаксис файла описания правил для хостов и сетей.
В качестве примера смотри файл /etc/hlf/conf.d/main/conf/lan.conf в исходниках.
Файл должен иметь синтаксис perl-скрипта. В файле должен быть один раз описан массив с зарезервированным именем @items. Каждый элемент массива @items описывает метаданные, правила фильтрации и управления трафиком для хоста или некоей логически связанной группы ip-адресов одной из сетей, описанных в networks.conf. Порядок элементов в @items важен и напрямую влияет на порядок генерируемых правил.
@items = (
описание_хоста,
описание_хоста,
...
описание_хоста
}
Описание_хоста представляют собой хэш из элементов со следующими возможными ключами:
{name => 'boss',
ou => 'Organization',
ln => 'LastName',
fn => 'FirstName',
mn => 'MiddleName',
email => 'box\@host.domain',
rules => список_правил
}
Список_правил представляет собой массив, в котором каждый элемент описывает набор правил для некоего ip-адреса или группы ip-адресов.
{name => 'boss',
ou => 'Organization',
ln => 'LastName',
fn => 'FirstName',
mn => 'MiddleName',
email => 'box\@host.domain',
rules => [
набор_правил_№1,
набор_правил_№2,
...
набор_правил_№N
]
}
Набор_правил представляют собой хэш из элементов со следующими возможными ключами:
- name - наименование данного набора правил. Необязательный параметр;
- srcnet - задает имя сети-источника для правил. Обязательный параметр;
- dstnet - задает имя сети-назначения для правил. Обязательный параметр;
- srcip - задает IPv4-адрес источника в сети srcnet для правил. Необязательный параметр;
- dstip - задает IPv4-адрес назначения для правил. Необязательный параметр;
- allow - список разрешающих правил. Необязательный параметр;
- deny - список запрещающих правил. Необязательный параметр;
- limit - список правил, ограничивающих темп новых подключений. Необязательный параметр;
- speed - список правил управления трафиком (скорость/приоритет). Необязательный параметр;
- classify - список правил классификации трафика. Необязательный параметр;
rules => [
{srcnet => 'lan', dstnet => 'inet', srcip => '192.168.0.10', name => 'workstation',
allow => список_разрешающих_правил,
deny => список_запрещающих_правил,
limit => список_темп_правил,
speed => список_скоростных_правил,
classify => список_правил_классификации
},
]
Некоторые пояснения.
Так как каждый элемент в @items можно рассматривать как описание хоста,
а хост может иметь неcколько адресов, то наборов_правил может быть несколько -
каждый набор описывает правила для одного из адресов хоста.
Зачем необходимо явно задавать сети (srcnet, dstnet)
если есть адреса srcip, dstip, по которым их можно вычислить?
Потому что могут быть правила в которых нет явных IP-адресов как показано ниже.
{name => 'icmp allow all',
rules => [
{srcnet => 'dmz', dstnet => 'inet',
allow => [{proto => 'icmp'}]
},
{srcnet => 'inet', dstnet => 'dmz',
allow => [{proto => 'icmp'}]
},
{srcnet => 'lan', dstnet => 'dmz',
allow => [{proto => 'icmp'}]
}
]
},
И для их написания проще использовать имена сетей, чем писать IPv4-адреса этих сетей. Т.е. имена сетей, для которых задаются правила, является первичной информацией, а IP-адреса вторичны и необходимы в основном для указания конкретного хоста в сети, но не для задания сетей.
Кроме того, не для всех случаев достаточно указать адрес сети. Например сеть INET (Интернет) в используемом здесь подходе невозможно описать каким-то одним конкретным адресом сети или группой адресов. Для шлюза Интернет можно описать как все не private-сети известные шлюзу и в том числе не DMZ. "Известные шлюзу" фактически значит все сети, указанные в таблицах маршрутизации шлюза. Т.о. все сети, которые не входят в таблицы маршрутизации шлюза и будут Интернетом. В таком случае надо будет указывать целый список адресов, что не очень практично и реализуемо разве что при помощи ipset, который пока в данном фаерволе не поддерживается. Несмотря на то что сеть DMZ имеет публичные адреса её мы тоже не относим к сети Интернет только потому, что для шлюза это особенная сеть - она маршрутизируется через сам шлюз, а не находится "где-то там шлюзом по умолчанию".
Список_разрешающих_правил представляет собой массив из хэшей, в котором каждый хэш описывает одно разрешающее правило:
allow => [
разрешающее_правило_№1,
разрешающее_правило_№2,
...
разрешающее_правило_№N
]
Разрешающее_правило позволяет разрешить создание
новых соединений, ограничить темп создания новых соединений и включить
лимитирование логирование пакетов соединений, превысивших заданный темп.
По сути каждое правило разворачивается в одну или две команды вида:
iptables -A...{условие_соответствия} -m hashlimit ... -j ALLOW
iptables -A...{условие_соответствия} -m limit ... -j LOG
Разрешающее_правило представляет собой хэш в котором допустимы следующие ключи:
- srcip - ip-адрес источника (см. --source);
- dstip - ip-адрес назначения (см. --destination);
- proto - протокол (см. --protocol);
- sport - порт источника (см. --sport);
- dport - порт назначения (см. --dport);
- tcp_flags - TCP-флаги (см. -m tcp --tcp-flags);
- hashlimit - включает и задает ограничение на темп создания новых подключений. Новые покдлючения разрешаются если их темп не выше заданного (см. -m haslimit --hashlimit);
- hashlimit-burst - (см. --hashlimit-burst);
- hashlimit-mode - режим учета соединений (см. --hashlimit-mode);
- hashlimit-name - наименование для данного ограничения(см. --hashlimit-name);
- loglimit - включает логирование (-j LOG) факта превышения темпа новых подключений и задает лимит на кол-во лог-сообщений в единицу времени (см. -m limit --limit);
- loglimit-burst - (см. --limit-burst);
- log-prefix - задает текст префикса для лог-сообщения(см. LOG target --log-prefix);
Список_запрещающих_правил представляет собой массив из хэшей, где каждый хэш описывает одно запрещающее правило:
deny => [
запрещающее_правило_№1,
запрещающее_правило_№2,
...
запрещающее_правило_№N
]
Запрещающее_правило позволяет запретить те или иные пакеты.
Запрещающие правила приоритетнее разрешающих правил. Поэтому для
запрещающих правил возможно задание исключений.
Запрещающее_правило представляет собой хэш в котором допустимы следующие ключи:
- srcip - ip-адрес источника (см. --source);
- dstip - ip-адрес назначения (см. --destination);
- proto - протокол (см. --protocol);
- sport - порт источника (см. --sport);
- dport - порт назначения (см. --dport);
- tcp_flags - TCP-флаги (см. -m tcp --tcp-flags);
- limit - включает логирование срабатывания DROP-правила и задает ограничение на количество лог-сообщений в заданный промежуток времени(см. -m limit --limit);
- limit-burst - (см. --limit-burst);
- log-prefix - задает текст префикса для лог-сообщения(см. LOG target --log-prefix);
- exclude - список исключений из данного запрещающего правила;
Исключение из запрещающего правила представляет собой хэш в котором допустимы следующие ключи:
Список_темп_правил представляет собой массив из хэшей, в котором каждый хэш описывает одно правило, ограничивающее кол-во новых соединений в единицу времени:
limit => [
темп_правило_№1,
темп_правило_№2,
...
темп_правило_№N
]
Темп_правило позволяет ограничить темп создания новых соединений и включить
лимитированное логирование пакетов соединений, превысивших заданный темп.
По сути каждое правило разворачивается в три команды команды вида:
iptables -A...{условие_соответствия} -m hashlimit ... -j RETURN
iptables -A...{условие_соответствия} -m limit ... -j LOG
iptables -A...{условие_соответствия} ... -j DROP
Темп_правило представляет собой хэш в котором допустимы следующие ключи:
- srcip - ip-адрес источника (см. --source);
- dstip - ip-адрес назначения (см. --destination);
- proto - протокол (см. --protocol);
- sport - порт источника (см. --sport);
- dport - порт назначения (см. --dport);
- tcp_flags - TCP-флаги (см. -m tcp --tcp-flags);
- hashlimit - включает и задает ограничение на темп создания новых подключений. Новые покдлючения разрешаются если их темп не выше заданного (см. -m haslimit --hashlimit);
- hashlimit-burst - (см. --hashlimit-burst);
- hashlimit-mode - режим учета соединений (см. --hashlimit-mode);
- hashlimit-name - наименование для данного ограничения(см. --hashlimit-name);
- loglimit - включает логирование (-j LOG) факта превышения темпа новых подключений и задает лимит на кол-во лог-сообщений в единицу времени (см. -m limit --limit);
- loglimit-burst - (см. --limit-burst);
- log-prefix - задает текст префикса для лог-сообщения(см. LOG target --log-prefix);
Список_скоростных_правил представляет собой массив из хэшей, в котором каждый хэш описывает одно правило, ограничивающее скорость для данного хоста/сети в восходящем или нисходящем направлениях:
speed => [
скоростное_правило_№1,
скоростное_правило_№2,
...
скоростное_правило_№N
]
Скоростное_правило представляет собой хэш в котором допустимы следующие ключи:
- dir - направление, для которого происходит ограничение. Обязательный параметр. Допустимы два значения:
- down - генерируются классифицирующие правила для нисходящего потока;
- up - генерируются классифицирующие правила для восходящего потока;
- rate - гарантированная скорость (см. HTB rate). Обязательный параметр;
- ceil - максимальная скорость (см. HTB ceil). Обязательный параметр;
- parent - идентификатор родительского класса, к кторому будет прикреплен данный (см. tc class parent). Обязательный параметр;
- out - исходящий интерфейс, на котором будет осуществляться данное ограничение:
- srcip - ip-адрес источника (см. --source);
- dstip - ip-адрес назначения (см. --destination);
- sport - порт источника (см. --sport);
- proto - протокол (см. --protocol);
- sport - порт источника (см. --sport);
- dport - порт назначения (см. --dport);
- tcp_flags - TCP-флаги (см. -m tcp --tcp-flags);
- other - позволяет задать другие параметры для генерируемой команды tc class add;
- classid - идентификатор данного класса (см. tc class classid);
- script - имя пользовательского perl-скрипта для генерации классифицирующих правил. При задании скрипта не происходит генерации правила классификации на основании srcip, dstip, sport, dport, tcp_flags;
Подразумевается использование HTB-дисциплины на целевом интерфейсе с заранее сконфигурированной (напр. отдельным скриптом) статической иерархией классов, в которую и будут добавляться генерируемые правила. Соответственно подерживается управление трафиком только на исходящем интерфейсе, policing на входящем не поддерживается.
Каждое скоростное правило вызывает генерацию одного классифицирущего правила для для таблицы mangle iptables и одного правила создания класса для команды tc.
Список_правил_классификации представляет собой массив хэшей, в котором каждый хэш позволяет задать классифицирующее правило в формате комнады iptables или имя пользовательского perl-скрипта, который генерирует нужный набор правил. в восходящем или нисходящем направлениях:
classify => [
правило_классификации_№1,
правило_классификации_№2,
...
правило_классификации_№N
]
Правило_классификации представляет собой хэш в котором допустимы следующие ключи:
- rule - позволяет явно задать фрагмент правила iptables без указания команды и имени цепочки. Команда будет добавлена в цепочку потока таблицы mangle;
- script - имя пользовательского perl-скрипта для генерации классифицирующих правил.
Конфигурация main
Конфигурация main собственно и является конфигурацией фаервола, в которой реализованы подходы, рассмотренные в первой части.
Основная конфигурация, рассматриваемая в данном тексте называется main и расположена она соответственно в /FW/conf.d/main. В этом же каталоге, наряду с обязательным скриптом start расположены и другие вспомогательные скрипты, задающие некоторые наборы правил, перезапускающие firewall по частям и т.д. Конфигурационные же файлы, для удобства, вынесены в отдельный подкаталог /FW/conf.d/main/conf.
Данное разделение является произвольным и определяется, тем какой именно код вы напишите в скрипте start и других скриптах (если таковые будут). Другими словами количество скриптов, конфигурационных файлов (кроме обязательных) и их расположение внутри каталога конфигруции абсолютно произвольное.
Конфигурация main расположена в каталоге /FW/conf.d/main и состоит из скриптов и конфигурационных файлов, расположенных в каталоге /FW/conf.d/main/conf .
Процесс загрузки конфигурация main
После загрузки ядра система инициализации выполняет скрипты для текущего runlevel. Для запуска фаервола при загрузке ОС добавляем символическую ссылку на /FW/modules/fw-sysv, например в /etc/rc3.d, который собственно и запускает скрипт /FW/start. Так как при этом скрипту /FW/start никакого имени конфигурации не передается, то /FW/start запускает скрипт /FW/conf.d/default/start. При этом ссылка default указывает на /FW/conf.d/main.
Perl-скрипт /FW/conf.d/main/start уже является специфичным для конфигурации main и через вызовы вспомогательных функций конфигурирует фаервол под конкретные задачи. Если вы захотите написать свою собственную конфигурацию, отличную по количеству сетей, интерфейсов, конфигурационных файлов, то в этот файл надо будет вносить изменения.
В скрипте /FW/conf.d/main/start, после подготовительных действий и объявления переменных идет вызов функции check_confs из /FW/modules/firewall.pm. Эта функция просто проверят правильность синтаксиса всех perl-скриптов, находящихся в /FW/conf.d/main/conf/. Файлы проверяются только на соответствие синтаксису языка - никакой смысловой проверки не проводится.
Далее выполняется функция init из того же firewall.pm, которая должна инициализировать конфигурацию интерфейсов шлюза и сетей, подключенных к ним. Для этого ей передается имя файла конфигурации сетей, в данном случае /FW/conf.d/main/conf/networks.conf. Так как подразумевается что это просто perl-скрипт (см. Файл, описывающий шлюз и сети), то данный файл просто выполняется как обычный perl-скрипт. Т.о. создается и инициализиурется хэш %networks.
Следующим выполняется bash-скрипт из другой конфигурации /FW/conf.d/outbound_only/start, который загружает временный набор правил, позволяющих шлюзу делать исходящие соединения. Это необходимо, например, для разрешения DNS-имён.
Затем запускается скрипт /FW/modules/wait_dns, который задерживает дальнейшее выполнение кода до момента, когда станет доступен DNS-сервер провайдера. Подразумевается, что доступность DNS-сервера провайдера означает, что xDSL-модем №1 загрузился и установил соединение. Это необходимо в случае если запуск фаервола происходит после сбоя питания и модем включился одновременно с шлюзом (шлюз загружается быстрее, чем модем устанавливает соединение). После этого становится возможным разрешение имён хостов и дальнейшее выполнение скрипта фаервола. Если после некоторого числа попыток DNS-сервер так и остается недоступным выполнение скрипта продолжается.
Далее bash-скрипт /FW/modules/load_modules загружает необходимые модули ядра, а /FW/conf.d/main/sysctl устанавливает значения некоторых переменных ядра, необходимые для данной конфигурации.
И затем выполняется bash-скрипт /FW/conf.d/main/via_isp, который настраивает маршрутизацию через первого или второго провайдера, в зависимости от значения переменной в /FW/conf.d/main/conf/via_isp.conf.
Вслед за этим четыре раза вызывается функция flow - для каждого из имеющихся conf-файлов, описывающих хосты и правила для них. В результате вызовов данной функции в массивы @filter_rules, @mangle_rules, @nat_rules, @raw_rules сгенерированными строчками команд для iptables-restore.
Затем, с помощью функции add_rules_from_file к списку уже сгенерированных на данном этапе правил добавляются правила из файлов /FW/conf.d/main/conf/rules_nat_redirect, rules_nat_snat и rules_route. Правила в этих файлах написаны вручную.
Функция gen_main_rules генерирует все правила переходов в цепочки потоков из встроенных цепочек INPUT, OUNPUT, FORWARD для таблиц filter и mangle.
После этого из файла rules_main_extra добавляются правила, написаные вручную для цепочек INPUT, OUNPUT, FORWARD таблиц filter и mangle.
Далее, в фукнции finalize генерируются правила DROP, добавляемые в конец каждой ALLOW-цепочки и правила переходов в DROP-цепочки,добавляемые в конец каждой SKIP-цепочки. Отдельно генерируются переходы в цепочки счетчиков *_CNT.
К этому моменту полный набор сгенерированных правил iptables находится в массивах @filter_rules, @mangle_rules, @nat_rules, @raw_rules. Вызов функции load_rules загружает эти правила в ядро при помощи команды iptables-restore.
Далее вызов bash-скрипта tc-ifb0 конифигурирует HTB_дисциплину и основную иерархию классов на интерфейсе ifb0, где происходит управление трафиком в нисходящем направлении. Вызовы tc-eth0 и tc-eth2 перенаправляют трафик с интерфейсов eth0 и eth2 на ifb0. Следом, аналогичная последовательность вызовов tc-ifb1, tc-eth1, tc-eth3 конфигурирует ifb1, где происходит управление трафиком в восходящем направлении.
Ранее, при вызовах flow генерировались не только правила для iptables, но и в массив @tc_rules генерировались tc-команды индивидуальных ограничений для хостов сетей. Теперь функция load_tc_rules() выполняет эти команды в дополнение к командам предыдущего пункта.
Последняя функция generate_save_counters по настройкам в networks.conf генерирует из шаблона /FW/modules/save_counters скрипт сохранения значения счетчиков /FW/conf.d/main/var/save_counters, который далее регулярно вызывается через cron.
Подробнее о функциях firewall.pm
Вопросы без ответов
* В команде tc filter ... police ... flowid major:minor параметр flowid по документации является обязательным (хотя на практике оказывается его можно не указывать). Для egress задание flowid имеет смысл - задаем класс для трафика, который соответствует этому фильтру. Но фильтр то можно привязать и к ingress! В чём смысл flowid в фильтре, созданном в ingress !?
* Major во всех командах для одной qdisc должен быть одинаковым?
* После tc filter add dev eth0...action mirred egress redirect dev ifb0 весь трафик из egress(?) eth0 перенаправляется на ingress(?) ifb0. А какой интерфейс в этом случае является "выходным", например для iptables? По логике ifb0, хотя все таки, похоже eth0.
* Если посмотреть в исходники tc (m_police.c) то там можно увидеть следующее недокументированное actions:
... else if (matches(arg, "shot") == 0) res = TC_POLICE_SHOT;
В m_mirred.c можно увидеть следующее:
fprintf(stderr, "Usage: mirredКак это работает (т.е. смысл) нигде недокументировано. Есть только заученная мантра 'tc filter add dev ... action mirred egress redirect dev ifb0' для использования одной дисциплины на IFB. Это что, можно "полисить" входящий трафик с нескольких интерфейсов одной дисциплиной? И это реально работает?[index INDEX] \n"); fprintf(stderr, "where: \n"); fprintf(stderr, "\tDIRECTION := \n"); fprintf(stderr, "\tACTION := \n"); fprintf(stderr, "\tINDEX is the specific policy instance id\n"); fprintf(stderr, "\tDEVICENAME is the devicename \n");
* Безклассовая (согласно любой документации) дисциплина TBF однако имеет класс:
tc qdisc add dev ifb0 root handle 4: tbf limit 1500 rate 160kbps burst 1600 tc qdisc show dev ifb0 tc class show dev ifb0 получаем: qdisc tbf 4: root refcnt 2 rate 1280Kbit burst 1600b lat 4295.0s class tbf 4:1 parent 4:Что означает наличие класса в безклассовой дисциплине - непонятно. Например прикрепить к TBF-классу дочерние дисциплины PRIO (как в примере http://blog.edseek.com/~jasonb/articles/traffic_shaping/scenarios.html#guarprio ) или HTB не получается. Прикрепить дочерний класс тоже непонятно можно ли, какой и зачем.
TODO
Текст
- описать из-за stateful уже созданные соединения будут существовать несмотря на
последующие запреты и их надо явно удалять (conntrack -D);
- упомянуть почему в реализации INET_SKIP_OR_DENY идут до RELATED,ESTABLISHED;
- возможность подсчета трафика с помощью conntrackd?;
- упомянуть про поток типа LAN>GW>LAN (маршрутизация через шлюз в одну и ту же сеть);
- Резервирование и переключение - разаобраться, что можно сделать;
- Policing закончить. Использование policing для входяещего трафика не дало нужных результатов;
Код
- удаление возможных существующих соединений (conntrack -D) при отсутствии хотя бы одного разрешающего правила;
- добавить возможность использования ipset. В штатном ядре Debian 7 уже есть ipset,
так что можно начинать прикручивать;
- --multiport;
- рефакторинг длинных процедур?;
- реализовать _default;
- в случае отсутствия DNS явно не загружать правила с именами вместо адресов - надо ли?;
- откат к предыдущему состоянию фаервола в случае неудачной загрузки команд iptables;
необходимо так как правила для отдельных таблиц загружаются независимо и возможна загрузка в таблицу filter
и затем ошибка при загрузке в mangle, но filter так и останется в новом состоянии